안녕하세요, NVIDIA DEEP LEARNING INSTITUTE REVIEW를 진행하고 있는 이제영입니다.
세번째 시간입니다! 이번엔 Image Super Resolution Using AutoEncoder Review로 돌아왔습니다!
이번주는 특이하게 인증서가 나오지 않았는데요, 반면 난이도는 꽤나 쉬운 편이었다고들 합니다!
의외였던건 다른 스터디 인원들은 Auto Encoder를 기존에 이름만 듣고 직접 공부해본 적은 없다고 하던데, 구조 자체는 많이 봤었다고 하네요.
Auto Encoder는 굉장히 중요한데, 이번 기회로 한번 다시 볼 수 있게되었습니다!
많이 부족하지만 앞으로도 잘 부탁드리겠습니다.
질문있으시면 언제든지 메일을 보내주세요! 기다리고 있겠습니다.
Review

Index
-Summary
-Experience
Summary
Image Super Resolution Using AutoEncoder
Image Super Resolution Using AutoEncoder Review
안녕하세요, NVIDIA DEEP LEARNING INSTITUTE REVIEW를 진행하고 있는 이제영입니다.
세번째 시간입니다! 이번엔 Image Super Resolution Using AutoEncoder Review로 돌아왔습니다!
이번주는 특이하게 인증서가 나오지 않았는데요, 반면 난이도는 꽤나 쉬운 편이었다고들 합니다!
의외였던건 다른 스터디 인원들은 Auto Encoder를 기존에 이름만 듣고 직접 공부해본 적은 없다고 하던데, 구조 자체는 많이 봤었다고 하네요.
Auto Encoder는 굉장히 중요한데, 이번 기회로 한번 다시 볼 수 있게되었습니다!
많이 부족하지만 앞으로도 잘 부탁드리겠습니다.
질문있으시면 언제든지 메일을 보내주세요! 기다리고 있겠습니다.
Review
Index
-Summary
-Experience
Summary
Image Super Resolution Using AutoEncoder
Super Resolution은 무엇일까요?
Low Quality Image를 고품질 고해상도 이미지로 변환하는 것입니다.
이미지의 해상도를 늘리려면(Upscaling), 커진 해상도에 따라 정보가 없는 픽셀은 어떻게 보간해야할까요?
전통적으로는 인접 픽셀의 값을 그대로 사용하였지만, Deep Learning을 이용하면 좀 더 자연스럽게 이미지를 Upscaling 할 수 있습니다.
이번 챕터에서는 AI-based Super Resolution을 진행 해 볼 예정입니다.
이는 기존의 Non-AI Methods들 보다 굉장히 높은 성능을 냅니다.
Deep Learning이 Upscaling을 학습하려면 Encoder와 Decoder를 사용한 모델을 학습해야합니다.
keras를 사용하여 Autoencoder를 학습해봅시다. 그리고 전통적인 Upscaling 방식과 비교해봅시다.
Introduction
Image의 품질 하락에 영향을 주는 요소는 여러가지가 있지만, 이번 강의에서는 Low-Resolution Image에 대해 화질을 개선할 것입니다.
실제로 천문학이나 단층 촬영과 같은 많은 분야에서 획득된 이미지는 유물과 소음을 포함하고 종종 낮은 해상도를 가집니다.
이러한 감쇠는 센서의 제한에서 비롯되는 경우가 많습니다.

How to improve a low quality image
AI-based methods들이 성능이 좋은 이유는 일반화를 잘하기 때문입니다.
이번 챕터에서는 AutoEncoder를 사용합니다.
AutoEncoder는 Artificial Neural Networks의 한 종류입니다.
Autoencoders
AutoEncoder란 무엇일까요?
그림을 먼저 보겠습니다.
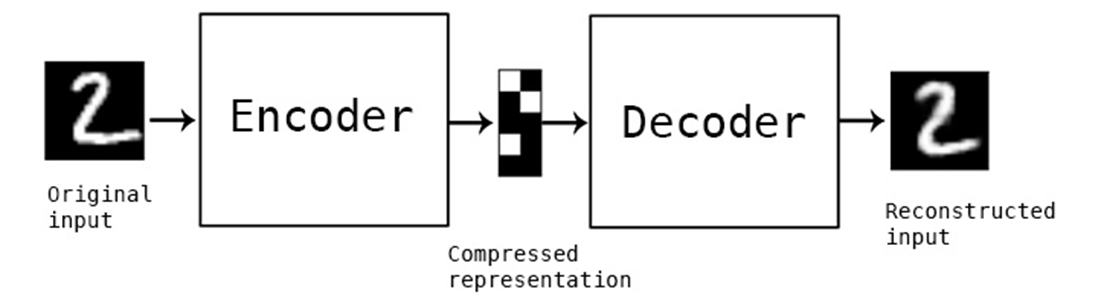
Autoencoders는 AI의 “identity functions”입니다.
데이터를 입력받으며 무언가를 수행합니다. 그리고 원본의 입력을 다시 반환합니다.
더 작은 feature space를 위해 데이터를 압축한다는 것이 autoencoders가 압축에 유용하다는 것을 의미하진 않습니다.
Autoencoders는 입력 데이터를 다른 space로 encode하는데, 이는 어쨌든 손실이 일어난다는 의미입니다.
What makes up an autoencoder?
- Autoencoder는 아래와 같이 구성됩니다. :
- Encoder
- 보통 클래식한 뉴럴 네트워크 입니다.
- Input의 차원을 줄입니다.
- Decoder
- 보통 클래식한 뉴럴 네트워크 입니다.
- 새로운 공간에 이미지를 복원하려고 합니다.
- Loss Functions
- 입력과 출력 사이의 차이(혹은 거리)를 묘사하는 방법입니다.
What kind of data does an Autoencoder manipulate
Autoencoder는 손실 압축이지만 우리는 이점을 얻습니다.
이번 강의에서 예를 들면, 우리는 low quality image information에 대해 손실을 가지며, 새로운 선명한 image로 재건하는 것입니다.
어떻게 autoencoder가 위의 손실을 학습할까? Autoencoder는 다양한 이미지들의 한 쌍에 대해서 패턴을 찾아야합니다. 어떻게 autoencoder가 위의 손실을 학습할까? Autoencoder는 다양한 이미지들의 한 쌍에 대해서 패턴을 찾아야합니다.
지금 부터 우리가 사용할 모델과, 그 결과를 살펴 보겠습니다!
사용된 코드와 설명은 직접 DLI를 수강하셔서 보시길 바랍니다!
이번엔 이런 구조의 아키텍쳐를 사용했고, 이런결과가 나왔음을 그림으로 보여드리겠습니다!
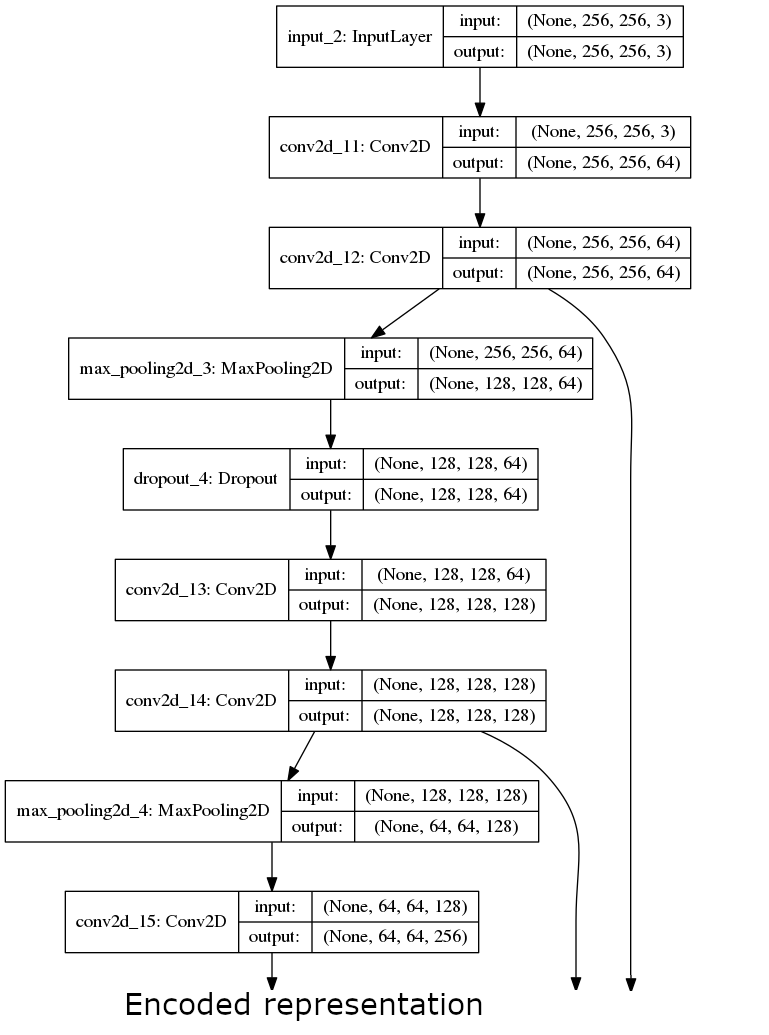
The Encoder
The Decoder
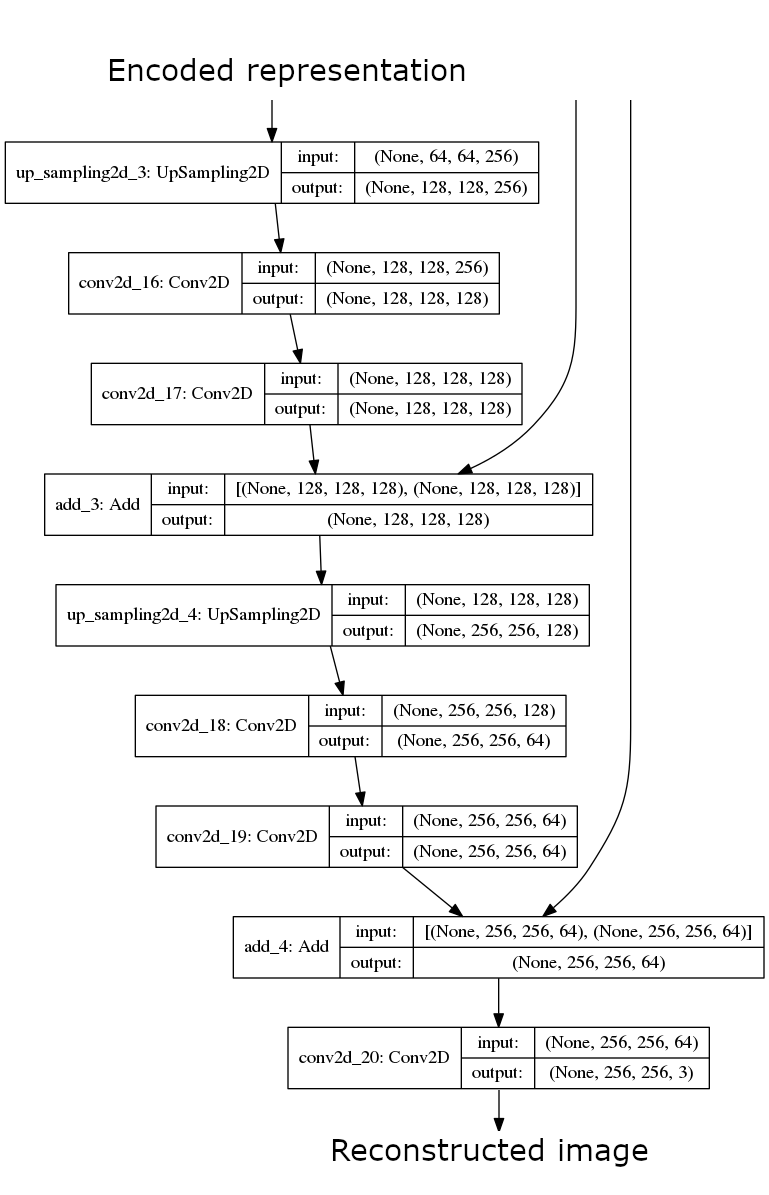
The Model
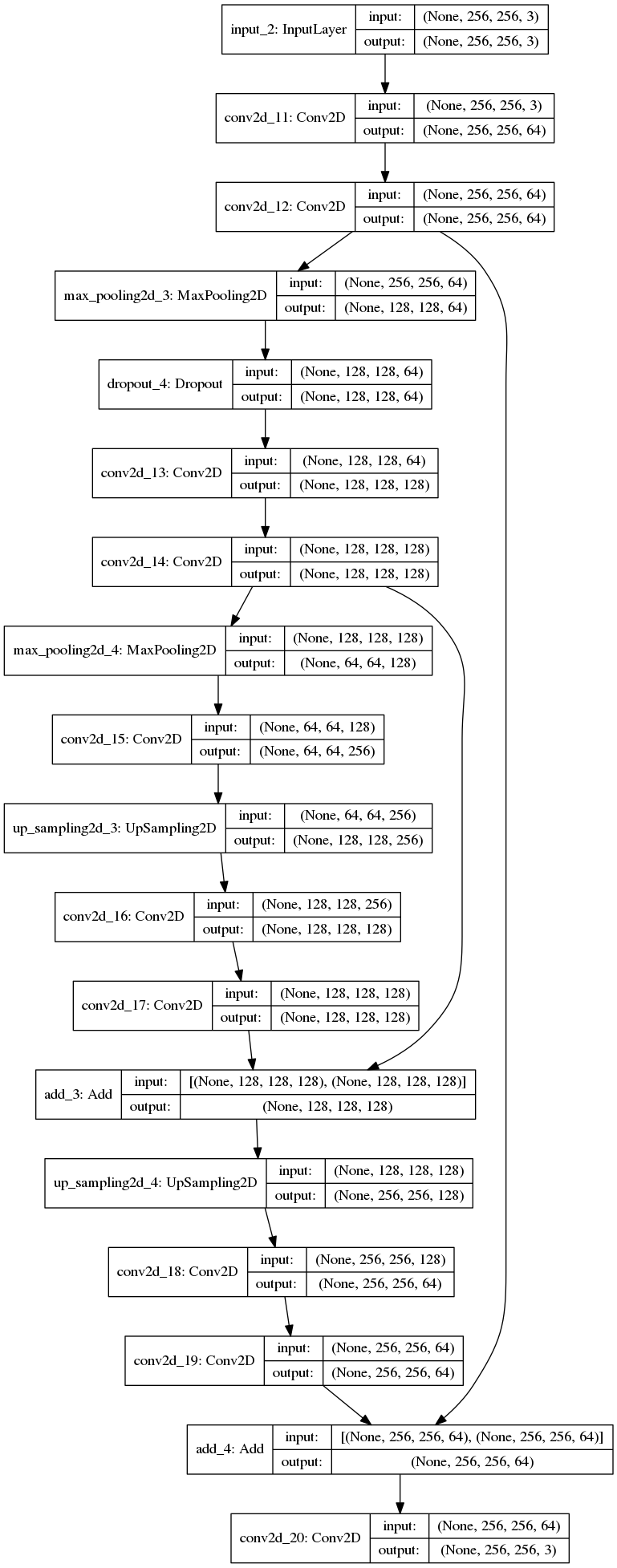
Display the results
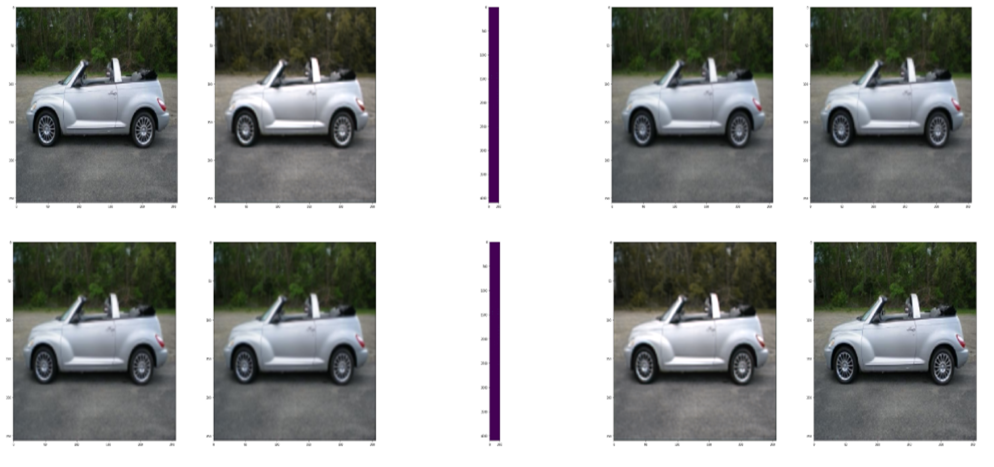
How to measure image quality
두 이미지의 시각적 질의 차이를 논하기 위해, loss function을 정의해야합니다.
이번 section에서는 두 이미지 사이의 차이에 대한 loss function에 대해 살펴봅니다.
MSE
Mean Squared Error는 값이 0이라면 차이가 없음을 나타냅니다.
MSE는 이미지의 밝기값에 민감하다는 단점이 있지만 high_res 와 low_res 이미지를 비교하기엔 충분합니다.
SSIM
Structural similarity(SSIM)는 TV 또는 그러한 미디어에서 다루어질 두 이미지 사이의 유사도를 측정합니다.
SSIM은 [1, -1]사이의 값을 가집니다.
여기서 1은 두 이미지가 유사함을 의미하고 값이 낮을수록 큰 차이가 있다는 것을 알려줍니다.
SSIM는 이미지 안의 작은 영역을 정해서 두 이미지를 비교합니다.
PSNR
Peak signal-to-noise ratio는 MSE를 이용하여 정의된 metric입니다.
PSNR은 reconstruction의 lossy compression의 질을 측정하기 위해 대개 사용됩니다.
Low resolution과 pixelization은 압축의 한 형태로 여겨질 수 있습니다.
노이즈가 없다면, PSNR은 무한대의 값을 가진다. 그래서 우리는 PSNR을 최대화 해야합니다.
HFENN
HFENNHigh Frequency Error Norm Normalized) metric은 두 이미지 사이의 고주파 디테일이 차이가 나는지 측정합니다.
이것은 이미지가 더 많은, 혹은 더 적은 high frequency details을 지니는지 추정할 수 있게 만듭니다.
출력 값이 0이면 서로 같습니다. 값이 크면, 두 이미지 사이에 perceptual difference가 존재합니다.
What to remember
AutoEncoder는 Deep Neural Networks입니다.
Autoencoder는 데이터를 작은 공간으로 인코딩합니다.
Autoencoder는 두 이미지 사이에서 인코딩 할 표현의 패턴을 찾습니다.
네트워크 아키텍쳐는 경험적으로 만듭니다.
Loss와 Metrics들은 학습에 굉장히 중요한 요소로 사용됩니다.
Experience
Experience-구정수
Autoencoder와 encoder, decoder에 대한 자세한 설명이 인상적이었다.
convolution layer와 upsampling, downsampling, dropout, merge layer에 대해 개념적으로 잘 설명되어 있어서 쉽게 이해할 수 있었다.
중간 과정에서 데이터를 시각화하여 볼 수 있어서 더욱 쉽게 이해되었다.
두 이미지를 비교하는 loss metrics를 여러가지 소개해주어서 새롭게 배웠다.
CNN을 막 배우고 어떻게 활용되는지 알아보고 싶은 학생들에게 추천하고 싶다.
Experience-이제영
Auto Encoder의 중요한 부분만 잘 찝어낸 것 같다.
케라스로 표현하여 쉽게 표현했다.
다양한 부가 기법들을 소개해주었다.
처음 시작하는 단계 사람들에게 추천할만 한 것 같다.
내용이 많지는 않았다.
Experience-박경훈
짧은 강의이기 때문에 깊은 내용은 알 수 없다.
해상도를 높이는 과정을 간략하게 알 수 있다.
간단한 예제를 하기 때문에 크게 다가오지 않는다.
기본적으로 딥러닝에 대한 기초가 있는 사람이 수강하는걸 추천한다.
긴 글 읽어주셔서 감사합니다! 내용이 적다고 생각했는데, 다들 자세하게 다뤄주어서 길어졌습니다!
마찬가지로 모든 리뷰는 주관적이라는점 알아주시면 감사하겠습니다!
앞으로 저희의 리뷰를 통해 Nvidia에서 열리는 DLI 프로그램에 대해 궁금하신점을 해결해가셨으면 좋겠습니다!
리뷰는 내용 요약이 들어가있지만, 실제로 DLI프로그램을 진행하면 직접 코딩하시면서 하실 수 있습니다.
언제나 처럼 이런 흐름이다~ 라고 생각하시고 보시면 좋을 것 같습니다, 감사합니다!
다음주에는 Fundamentals of Accelerated Computing with CUDA Python리뷰로 돌아오겠습니다!

Comments