0. 시작하며
안녕하세요, 가톨릭 대학교 박사 과정 이제영입니다.
혹시 여러분들은 NVIDIA Tech Blog를 구독 하시나요? 저는 NVIDIA에서 Ambassador로 활동하고 있기 때문에, NVIDIA Tech Blog를 자주 보는 편입니다.
그 중 제가 주로 활동하고 있는 GPU-based Data Science와 관련한 글들은 실습까지 꼭 진행해 보는데요, 지난 2024년 12월 20일 RAPIDS를 RAY와 함께 사용하는 좋은 글이 올라왔습니다.Accelerating GPU Analytics Using RAPIDS and RAY LINK
실은 저는 RAPIDS를 사용할때 RAY를 굉장히 많이 활용하고 있습니다.
로
주로 RAY를 사용한 Hyper Paramter Optimization을 자주 수행하는데요, RAY Tune을 RAPIDS와 함께 사용하면 굉장히 빠른 속도로 HPO를 수행할 수 있습니다.
따라서 오늘은 RAY와 RAPIDS를 사용한 Data Engineering Pipelines 실습과 XGBoost를 사용하여 Hyper Parameter Optimization까지 진행 해보려 합니다.
혹시 아직 RAPIDS를 사용하는데 익숙치 않거나 GPU-based Data Science/Engineering이 어려우신 분들은 기회가 된다면 제가 blog로 정리해두겠습니다.
1. RAY
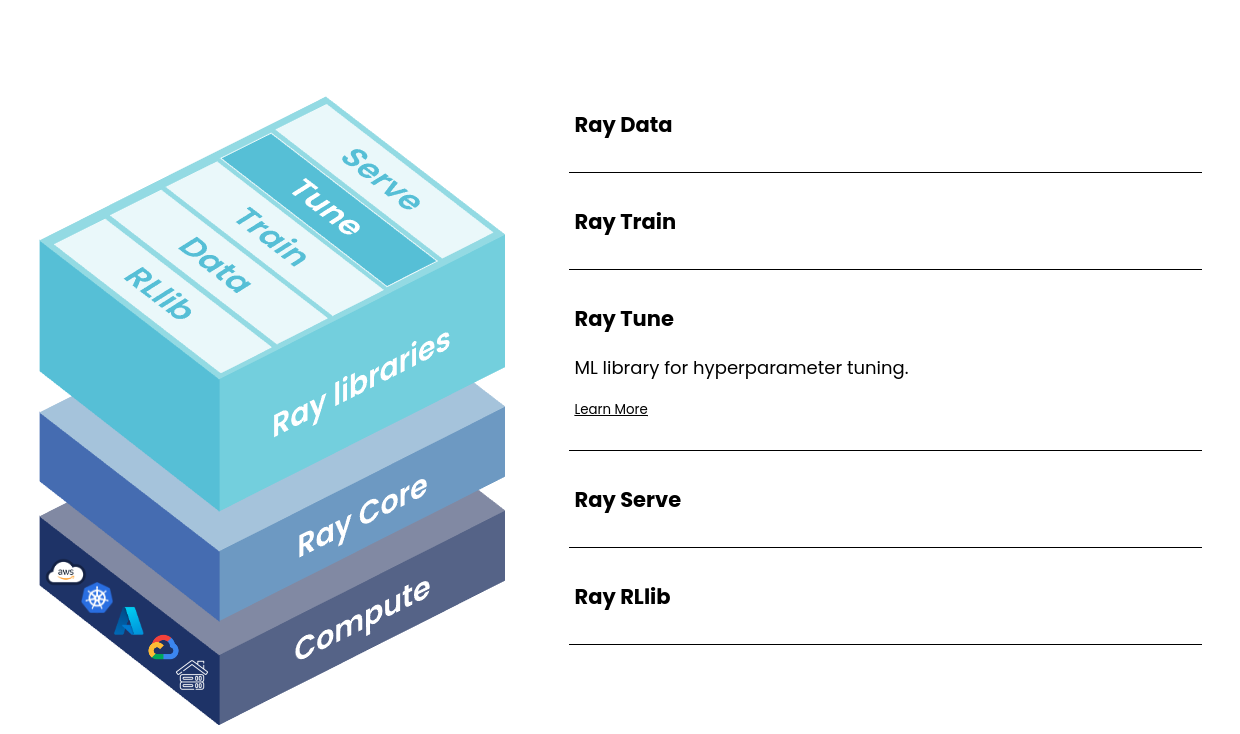 <Figure 1. RAY>
<Figure 1. RAY>
RAY tune 라이브러리로 대표되는 RAY는 실은 다양한 라이브러리들이 묶여있는 하나의 platform입니다.
특히 RAY는 CPU/GPU를 활용한 병렬 처리 및 각종 연산 자원 분배, pipline 구성, 학습, 튜닝 등의 다양한 기능을 지원합니다.
이 중 오늘은 cuDF를 활용하여 데이터의 파이프라인을 구성하기 위해, RAY Core의 Actor를 활용합니다.
RAY core는 분산 어플리케이션을 구축하고 확장하기 위한 핵심 기본요소들을 제공하는 라이브러리입니다.
RAY Actor는 각 woker들이 데이터를 저장, 관리, 변형할 수 있도록 도와주는 클래스입니다.
이런 RAY Actor를 활용하여 GPU를 Management하고, 병렬 연산을 수행시킨다면 cuDF 라이브러리를 효과적으로 다룰 수 있게 됩니다.
한번 코드를 직접 볼까요?
@ray.remote(num_gpus=1)
class cuDFActor:
def __init__(self)->None:
...
def read_parquet(self, path:str) -> cd.DataFrame:
df = cd.read_parquet(path)
return df
# Start 4 Workers
pool_size = 4
actor_pool = [cuDFActor.remote() for i in range(pool_size)]
위의 코드는 간단한 Ray와 cuDF코드입니다.
RAY Actor는 파이썬의 데코레이터 형태로 선언할 수 있습니다.
또한 중요하게 봐야하는 부분이 몇가지가 있는데요, 우선 @ray.remote안의 num_gpus의 값입니다.
num_gpus는 사용가능한 gpu의 개수를 의미하는데요, 이 때 ray는 num_gpus를 소수의 형태로도 할당 할 수 있습니다.
즉 만약 num_gpus=0.5로 할당한다면, ray는 actor를 처리할 때 GPU 리소스의 절반만 활용하여 작업하게 됩니다.
다음으로 주의 깊게 봐야 하는 것은 Actor의 선언인데요. 을바로 actor_pool = [cuDFActor.remote() for i in range(pool_size)] 부분입니다.
기본적으로 RAY Actor를 활용하여 작업을 수행할 땐 다음과 같은 순서로 진행 되게 됩니다.
- RAY Actor Class 정의
- RAY Actor Class 할당
- RAY Actor Class 실행
따라서 현재는 이미 선언한 RAY Actor Class에 대하여 총 4개의 Worker가 작업하도록 할당하고 있는 것인데요.
만약 여러분들이 4개의 GPU가 있다면, RAY Actor는 한개의 Actor Class에 대해 한개의 GPU 전체 자원을 사용하여 작업할 것을 기대합니다.
그럼 만약에 어려분들이 4개의 GPU가 없다면 어떤일이 발생할까요? 이는 다음에 이야기하도록 하겠습니다.
2. Create Dataset
그러면 본격적으로 Sample Data를 활용하여 RAY와 cuDF를 써보도록 할까요?
이를 위해 classification용 예시 데이터를 만들어 보겠습니다.
import cupy as cp
import cudf as cd
import dask_cudf as dd
from cuml.datasets.classification import make_classification
column_names = [f"col_{i}" for i in range(100)] + ["target"]
dtypes = dict(zip(column_names, ['float32' for _ in range(100)] + ['int8']))
X, y = make_classification(n_samples=1000000, n_features=100, n_informative=4, n_classes=2, random_state=137)
df = cd.DataFrame(data = cp.concatenate([X, y[:, cp.newaxis]], axis=1), columns= column_names, dtype=dtypes)
df = dd.from_cudf(df, npartitions=4)
os.makedirs("./output", exist_ok=True)
df.to_parquet("./output/data")
실은 제가 분산 처리 혹은 병렬 처리를 한다면 주로 dask_cudf를 많이 사용합니다. 하지만 이번 단계에선 dask_cudf에 대한 이야기는 없을 예정입니다.
기회가 된다면 말씀드리면 좋지만, 결론적으로 현재 작업에서 dask_cudf와 RAY를 함께 사용하는 것은 썩 좋은 생각이 아닙니다.
지금은 우선 현재 코드에대해 이야기 해보도록 하겠습니다. 우리는 예시를 위해 100개의 feature를 가지고 1000000개의 인스턴스를 가진 데이터를 생성했습니다. 그리고 DataFrame화 시키기 위해 각 feature별로 “col_숫자”의 형태로 이름을 달았습니다. 마지막으로 class를 총 두개로 간단한 이진 문제를 푸는 데이터를 생성했습니다.
마지막으로 이렇게 만든 데이터에 대해 dask_cudf를 활용하여 4개의 파티션으로 나누고 parquet 파일 형식으로 저장하였습니다. 이렇게 저장하게 되면 parquet 파일은 총 4개가 생성 될 것입니다. 한번 볼까요?

<Figure 2. Sample Data Structure>
이렇게 생성된 4개의 parquet 파일을 읽고, XGBoost를 활용하여 학습해볼 예정입니다.
자, 그럼 여기서 문제입니다. 만약 여러분들이 cuDF나 Pandas를 가지고 4개의 parquet파일을 읽어 오려면 어떻게 해야할 까요??
가장 간단한 방법은 각 파일 별로 read_parquet한 후 concat하는 것입니다.
물론 나쁘지 않은 방법이지만 하나의 파일이 크면 클 수록 시간이 증가할 것입니다.
그렇다면 두번째 방법은 무엇일까요? 바로 cuDF를 이용하여 한번에 읽어오는 것입니다.
cuDF의 read_parquet는 여러개의 parquet파일을 읽어 하나의 DataFrame으로 병합하는 것을 지원하고 있습니다.
df = cudf.read_parquet('./output/data/*.parquet')
물론 첫번째 방법 보단 효율적이지만 근본적으로 순차적으로 읽어 온 후 병합한다는 사실은 변하지 않습니다.
그렇다면 어떻게 좀 더 효율적으로 읽어 올 수 있을까요??
가장 간단한 방법은 분산 처리하여 파일별로 별도로 읽어 올 수 있다면 효율적으로 읽어올 수 있을 것입니다.
하지만, cuDF는 기본적으로 단일 파티션, 하나의 GPU에서만 동작할 수 있는데 어떻게 하면 분산 처리할 수 있을까요??
이럴 때 우리는 RAY를 이용하여 분산 처리를 수행할 수 있습니다.
3. Read Dataset with RAY
from ray.util import ActorPool
@ray.remote(num_gpus=0.4)
class cuDFActor:
def __init__(self,
random_state:int = None
)->None:
...
# Create actors
num_actors = 4 # Number of Actors
actors = [cuDFActor.remote() for _ in range(num_actors)] # Remote Actors, Now We make remote gpus = 0.5, and use 1 T4 GPU so gpu run 2
pool = ActorPool(actors) # Make Acotr Pool Object
results = pool.map_unordered(
lambda actor, p: actor.read_parquet.remote(
path = p,
),
glob.glob(os.path.join("./output/data", "*"))
)
# Finally, we can obtain a cuDF DataFrame using Ray.
results = cd.concat(results)
print(results.head())
# print(results[0].heaead())
print("Read datasets Finished...")
간단합니다. 우리가 살펴본 actor를 사용하는 방법처럼 4개의 actor를 실행합니다. 그리고 연산을 도와줄 ActorPool을 사용합니다.
ActorPool은 Actor들에게 각종 Pool연산을 효율적으로 할 수 있도록 도와주는 모듈입니다.
우리는 그중 map_unodered() 매소드를 활용하여 각 데이터의 파일별로 actor한개에 할당하려고합니다. map_unodered()는 순서와 관계 없이 pool 연산을 진행하고 싶을 때 사용하는 메소드입니다.
현재 저는 2080 super 2대의 환경에서 진행하고 있으며, 각 gpu별로 0.4의 리소스를 가지고 4개의 actor가 2개의 GPU에서 작업하게 됩니다.
이경우 RAY는 자동적으로 최적화 하여 GPU에 할당 및 연산을 진행하며, 지금의 경우 두개의 GPU에 각각 0.4씩 총 4개의 Actor가 할당 될것입니다.
즉 4개의 파일을 GPU 2개가 한번의 연산으로 읽어올 수 있습니다..!
잘 읽어 왔는지 볼까요??
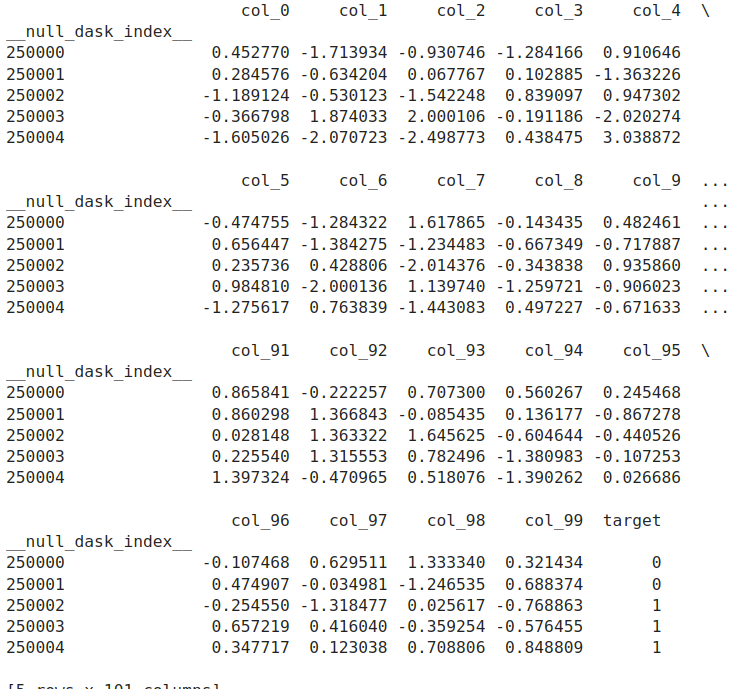
<Figure 3. Results>
제대로 읽어온 것을 확인할 수 있습니다.
다만, 현재 우리는 순서와 관계 없이 읽어오도록 코드를 작성했습니다.
따라서 현재 인스턴스는 우리의 예상과는 다르게 250000부터 시작하는 것을 확인할 수 있습니다.
우선 글이 길어지는 관계로 RAY와 RAPIDS는 다음에 Part-2 XGBoost HPO로 다시 돌아오도록 하겠습니다.
원본 코드는 조만간 공개하겠습니다.
읽어주셔서 감사합니다 :)
Jeyoung Lee
Assistant Professor at school of computing at Soongsil University. My research interests include EEG, Generate images, Computer Vision, GPU-based data science,Machine learning, and Deep learning.

Comments