안녕하세요, NVIDIA DEEP LEARNING INSTITUTE REVIEW를 진행하고 있는 이제영입니다.
네번째 시간입니다! 이번엔 Fundamentals of Accelerated Computing with CUDA Python Review로 돌아왔습니다!
이번주는 그 전에 진행했던 Fundamentals of Accelerated Computing with CUDA C/C++ 과 비슷하다는 느낌을 많이 받았다고 하는데요
내용 자체는 그 전과 크게 다르지 않으나 학기를 다니다보니 아무래도 조금 씩 늦어집니다.
앞으로도 시간을 잘 지킬 수 있도록 노력하겠습니다!
많이 부족하지만 앞으로도 잘 부탁드리겠습니다.
질문있으시면 언제든지 메일을 보내주세요! 기다리고 있겠습니다.
Review

Index
-Summary
-Experience
Summary
Introduction to CUDA Python with Numba
- 이번 챕터의 목표
- Numba를 활용하여 CPU에서 Python... read more
Fundamentals of Accelerated Computing with CUDA Python Review
안녕하세요, NVIDIA DEEP LEARNING INSTITUTE REVIEW를 진행하고 있는 이제영입니다.
네번째 시간입니다! 이번엔 Fundamentals of Accelerated Computing with CUDA Python Review로 돌아왔습니다!
이번주는 그 전에 진행했던 Fundamentals of Accelerated Computing with CUDA C/C++ 과 비슷하다는 느낌을 많이 받았다고 하는데요
내용 자체는 그 전과 크게 다르지 않으나 학기를 다니다보니 아무래도 조금 씩 늦어집니다.
앞으로도 시간을 잘 지킬 수 있도록 노력하겠습니다!
많이 부족하지만 앞으로도 잘 부탁드리겠습니다.
질문있으시면 언제든지 메일을 보내주세요! 기다리고 있겠습니다.
Review
Index
-Summary
-Experience
Summary
Introduction to CUDA Python with Numba
- 이번 챕터의 목표
- Numba를 활용하여 CPU에서 Python function들을 Compile 할 수 있습니다.
- Numba가 어떻게 Python Function들을 compile 하는지 알 수 있습니다.
- NumPy ufuncs GPU 가속화 할 수 있습니다.
- hand-written vectorized functions GPU 가속화 할 수 있습니다.
- CPU host와 GPU device간의 데이터 전송을 최적화 할 수 있습니다
- Numba란 무엇인가?
- Numba는 CPU 또는 GPU환경에서 numerically-focused Python을 가속화 하기 위한 just-in-time, type-specializing, function compiler입니다.
- function compiler
- Numba는 파이썬 함수를 컴파일합니다.
- 어플리케이션 전체를 컴파일하지 않습니다.
- Numba는 파이썬 인터프리터를 대체하지 않습니다.
- 단지 기존의 함수를 더 빠른 함수로 대체하는 파이썬 모듈일 뿐입니다.
- type-specializing
- Numba는 특수한 데이터 타입에 대해 특별한 구현을 생성하면서 함수를 빠르게 합니다.
- 파이썬 함수는 보편적인 데이터 타입에서 작동하도록 설계되어있습니다.
- 이는 매우 유연하지만 느립니다.
- just-in-time
- Numba는 처음 선언되면 함수를 번역합니다.
- 어떤 변수 자료형이 사용될 지 알아야합니다.
- 기존 어플리케이션과 마찬가지로 Jupyter 노트북에서 대화식으로 사용할 수 있습니다.
- numerically-focused
- 일반적으로 Numba는 Numerical Data 타입에 맞춰져 있습니다.
- 그러므로 String형 데이터에 매우 제한적이고, 많은 String형 사용사례가 GPU에서 작동하지 않습니다.
- Numba에서 좋은 결과를 얻으려면 Numpy 배열을 사용해야합니다.
How Numba Works
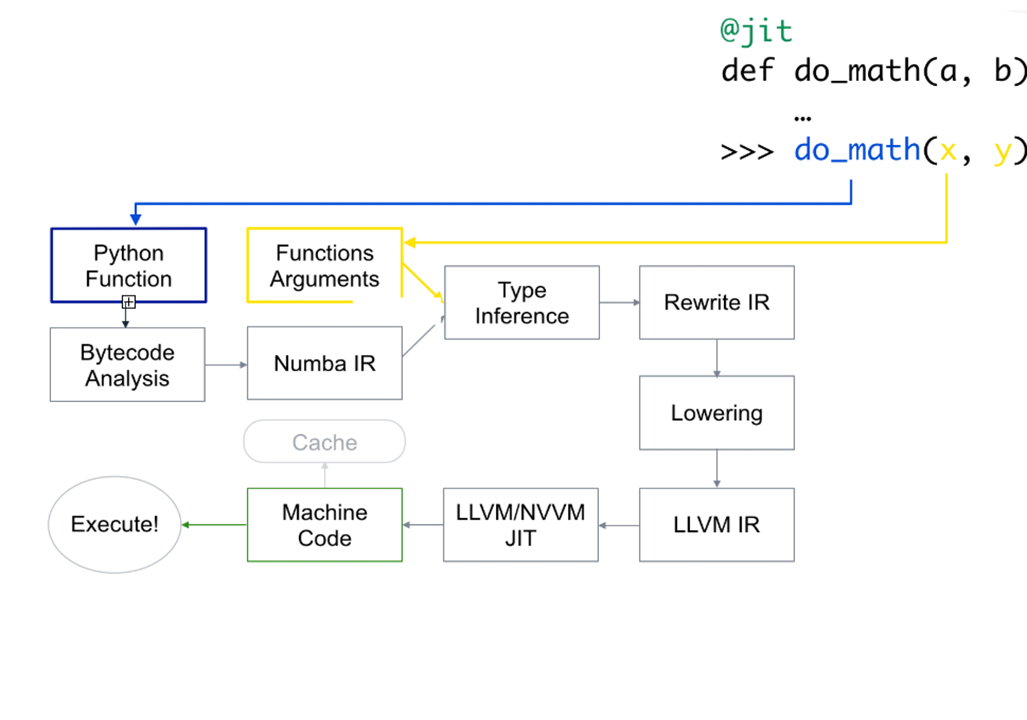
Numba 컴파일러는 function decorator를 사용하여 활성화할 수 있습니다.
Decorators는 함수를 변형합니다.
Numba에서의 CPU compilation decorator는 @jit입니다.
.py_func attribute를 통해 original python function을 호출할 수 있습니다.
@vectorize detorator를 사용하여 compiled ufuncs를 만들 수 있습니다.
특정 자료형을 지정하여 CUDA GPU에서 실행되도록 선언할 수 있습니다.
GPU가 CPU보다 느린 경우, 아래의 상황인지 살펴봅시다.
- 입력값이 너무 작은 경우
- 계산이 너무 간단한 경우
- GPU로 데이터를 복사하거나 읽어들일 경우
- 자료형이 필요 이상으로 클 경우
CUDA Device Arrays를 사용하여 GPU 내에 데이터를 저장할 수 있습니다.
Custom Kernels and Memory Management for CUDA Python with Numba
- 이번 챕터의 목표
- Python으로 커스텀 CUDA커널을 작성하고 실행합니다.
- Grid Stride Loops를 활용하여 대규모 DataSet에서 병렬로 작업하고 메모리를 통합 활용할 수 있습니다.
- atomic operations를 사용하여 병렬 작업시 race conditions를 회피합니다/
The Need for Custom Kernels
GPU에서 가속화되는 ufuncs를 사용하는 것 보다 더욱 힘든 일입니다.
custom CUDA kernels를 작성하는 것은 개발자에게 functions의 types에 대해 엄청난 유연성을 제공합니다.
Introduction to CUDA Kernels
CUDA로 프로그래밍 할 때 개발자는 병렬 커널 스레드의 GPU의 많은 코어에서 실행 되거나 CUDA 용어로 실행되는 커널이라는 GPU에 대한 함수를 작성합니다.
커널이 시작될 때 프로그래머는 "Excution Configuration"이라는 특수 구문을 사용하여 병렬 실행 구성을 설명합니다.
CUDA Thread Hierarchy
GPU에서 함수를 실행할 때 어떤 일이 일어나는지 알아봅시다.
GPU는 병렬로 작업을 수행합니다.
이러한 작업은 thread에서 수행됩니다.
여러 threads가 병렬로 동작한다. CUDA는 수 천개의 threads를 병렬로 처리할 수 있습니다.
threads의 집합을 block이라 한다. 여러 개의 block이 존재할 수 있습니다.
주어진 커널 실행에 대한 blocks의 집합을 grid라고 한다. GPU 함수를 kernel이라 부릅니다.
kernels는 execution configuration과 함께 실행됩니다.
execution configuration은 grid 안의 blocks의 수, 각 blocks의 threads의 수를 정의합니다.
한 grid 안의 모든 block은 같은 수의 threads를 가집니다.
grid > block > thread
CUDA-Provided Thread Hierarchy Variables
gridDim.x 는 grid 안의 blocks의 수입니다.
blockIdx.x 는 grid 안의 현재 block의 index입니다.
blockDim.x 는 block 안의 threads의 수입니다.
threadIdx.x 는 block 안의 thread의 index입니다.
An Aside on Hiding Latency and Execution Configuration Choices
CUDA 지원 NVIDIA GPU는 DRAM에 연결된 여러 개의 Streaming Multiprocessors 또는 SMs on a die로 구성됩니다.
SM에는 많은 CUDA 코어를 포함한 커널 코드 실행에 필요한 모든 리소스가 포함되어 있습니다.
커널이 시작되면 각 블록은 단일 SM에 할당되고 잠재적으로 많은 블록이 단일 SM에 할당됩니다.
SM은 블록을 "워프 (warps)"라고하는 32 개의 스레드로 세분화하고 실행하기 위해 병렬 명령이 제공되는 워프입니다.
따라서 GPU의 모든 잠재력을 활용하여 성능이 향상된 응용 프로그램을 작성하는 것이 가장 중요하기 때문에 SM이 커널을 실행하여 가장 간단하게 달성 할 수있는 충분한 수의 왜곡을 제공함으로써 대기 시간을 숨길 수있는 기능을 제공해야합니다.
그리드 및 블록 치수가 충분히 커야합니다.
Atomic Operations and Avoiding Race Conditions
다른 병렬 처리 프레임워크와 마찬가지로, CUDA 또한 race condition(경쟁 상태)가 발생할 수 있습니다
- read-after-write hazards
- 한 스레드가 다른 스레드가 쓰는 동안 메모리 위치를 읽는 중입니다.
- write-after-write hazards
- 두 개의 스레드가 동일한 메모리 위치에 쓰고 있으며 커널이 완료되면 하나의 쓰기 만 표시됩니다.
이러한 문제를 피하려면 CUDA kernel algorithm을 잘 짜야 합니다.
CUDA는 atomic operations를 제공합니다.
이를 활용하여 잘 피해갈 수 있습니다.
Multidimensional Grids and Shared Memory for CUDA Python with Numba
- 이번 챕터의 목표
- 다차원 블록 및 그리드를 사용하여 다차원 데이터 세트에서 GPU 가속 병렬 작업을 수행합니다.
- 공유 메모리를 사용하여 데이터를 칩에 캐시하고 느린 글로벌 메모리 액세스를 줄입니다.
2 and 3 Dimensional Blocks and Grids
blocks = 4 => blocks = (2, 2)
threads_per_block = 4 => threads_per_block = (2, 2)
2 and 3 Dimensional Blocks and Grids
grid = cuda.grid(1) => grid_y, grid_x = cuda.grid(2)
stride= cuda.gridsize(1) => stride_y, stride_x = cuda.gridsize(2)
Shared Memory
Nunba는 blocks 간의 threads 사이의 shared memory를 할당할 수 있습니다.
병렬 threads 읽기나 쓰기에서 shared memory는 필수입니다.
Shared memory를 선언할 때 shared memory의 크기를 설정해야 합니다.
이 크기는 정적인 값입니다.
temp = cuda.shared.array(4, dtype=types.int32)
idx = cuda.grid(1)
Experience
Experience-구정수
Experience-이제영
NUMBA가 C++보다 편했습니다.
다만 가독성이 C++보다 살짝 떨어지는 것 같다.
총속도가 얼마나 빠르진 감이 안 잡힌다.
C++은 못하겠고, CUDA는 해보고 싶으면 추천합니다.
CUDA만 해보고싶으면 차라리 C++로 가는게 좋을 것 같다.
Experience-박경훈
NUMBA의 사용법을 간략하게 알 수 있다.
C/C++ 가속화 컴퓨팅과 공통되는 부분이기 때문에 한 과정만 들어도 괜찮지만, C++ 과정이 좀 더 좋았다.
시험이 어려웠다.
Python을 다루는 분들에게 추천한다.
Experience-구정수
</center>Python으로 GPU에서 동작하는 CUDA 명령어를 사용할 수 있다는 사실이 흥미로웠다.
병렬 처리를 통해 기존의 연산보다 빠른 속도를 낼 수 있었다.
주어진 문제에 대한 설명이 좀 더 자세했으면 좋았을 것 같다.
Python 문법을 잘 알고 있는 사람에게 추천할 만하다.
인증서



긴 글 읽어주셔서 감사합니다! C++때 겹치는 부분이 많아 block, thread등의 그림은 첨부하지 않았습니다!
또 저희 친구들은 c++를 더 선호하는 경향이 있네요, 둘다 좋은 강의입니다!
마찬가지로 모든 리뷰는 주관적이라는점 알아주시면 감사하겠습니다!
앞으로 저희의 리뷰를 통해 Nvidia에서 열리는 DLI 프로그램에 대해 궁금하신점을 해결해가셨으면 좋겠습니다!
이렇게만 보시면 감이 안잡히실 수도 있지만! 실제로 DLI프로그램을 진행하면 직접 코딩하시면서 하실 수 있습니다.
이런 것들을 배우는 구나~ 가 더 중요하게 보셔야할 점인 것같습니다.
다음주에는 Fundamentals of Accelerated Data Science with RAPIDS리뷰로 돌아오겠습니다! 감사합니다!

Comments