안녕하세요, NVIDIA DEEP LEARNING INSTITUTE REVIEW를 진행하고 있는 이제영입니다.
드디어 두번째 시간이 다가왔습니다! 스터디를 이어가게 해주신 손해인님, Nvidia-Korea분들 모두에게 감사드립니다!
이번주는 저번주에 말씀드렸듯이 ACCELERATED COMPUTING WITH CUDA C/C++을 진행하였습니다.
기존에 CUDA 코딩과 관련하여 공부해보고 싶었지만 NVCC Document는 솔직히 저같은 초보자가 보기에는 조금 어려운 점이 많았습니다.
이번 스터디를 통해 관련한 내용을 조금이라도 배울 수 있어서 매우 의미 있는 시간이었습니다. 감사합니다!
많이 부족하지만 앞으로도 잘 부탁드리겠습니다.
질문있으시면 언제든지 메일을 보내주세요! 기다리고 있겠습니다.
Review

Index
-Summary
-Experience
Summary
Accelerating Applications with CUDA C/C++
CUDA는 세계에서 가장 성능이 뛰어난 병렬 프로세서인 NVIDA GPU에서 가속화되고 대량 병렬화된 코드를 실행할 수 있도록 해준다. 따라서 CUDA를 배운다면 CPU로는 불가능한 계산을 가능하게 해줍니다.
__global__ void GPUFunciont() : __global__ 키워드는 뒤에 함수가 GPU에서 실행된다는 것을 말합니다.
GPUFunction«<a, b, c, d, e»>() : GPU함수를 실행시킬 때 “«< … »>” 이런 기호를 쓰는데 a에는 블록 수, b에는 스레드 수, c에는 바이트 수, d에는 스트림, e에는 뭐라한다. 우린 이런 함수를 커널이라고 부릅니다.
cudaDeviceSynchronize() : 실행 커널은 비동기적이기 때문에 CPU 코드는 커널의 끝을 기다리지 않는다. 따라서 이 코드를 호출한다면 커널이 완료될 때까지 CPU코드를 기다리게 할 수 있습니다.
Writing Application Code for the GPU
cudaDeviceSynchronize() 이 코드를 어디에서 호출하냐에 따라 결과가 달라집니다.

Launching Parallel Kernels
<<< NUMBER_OF_BLOCKS, NUMBER_OF_THREADS_PER_BLOCKS>>>
grdiDim.x = NOB, blockDim.x = NOT, blockIdx.x = 특정 블록, threadIdx.x = 특정 스레드
커널을 이용해 다음과 같이 바꿔줄 수 있습니다.

Allocating Memory to be accessed on the GPU and the CPU
Malloc() 함수로 메모리를 할당 받은 포인터는 GPU 코드를 참조 할 수 없습니다.
GPU 코드를 실행하기 위해서는 cudaMallocManaged() 함수를 사용해야 하며 free() 함수 말고 cudaFree() 함수를 통해 해제를 해줘야한다.
Accelerated Computing Summary
- At this point in time you have accomplished all of the following lab objectives:
- C/C++을 이용하여 CPU functions와 GPU kernel 연결하는 프로그램을 쓰고, 컴파일하고, 돌려보았습니다.
- Execution Configuration을 사용하여 병렬 스레드 계층 제어를 해보았습니다.
- Loop 문을 리팩토링하여 GPU에서 병렬로 실행했습니다.
- CPU와 GPU에 메모리를 할당하고, 비우고를 해보았습니다.
- CUDA 코드를 이용한 Error Handling을 해보았습니다.
- Now you will complete the final objective of the lab:
- CPU-only applications을 가속화 하였습니다.
Iterative Optimizations with the NVIDIA Command Line Profiler
Nsys는 Nsight Systems 명령어 도구입니다.
응용 프로그램의 GPU 활동 요약, CUDA API 호출 및 Unified Memory 활동에 대한 정보를 출력해줍니다.
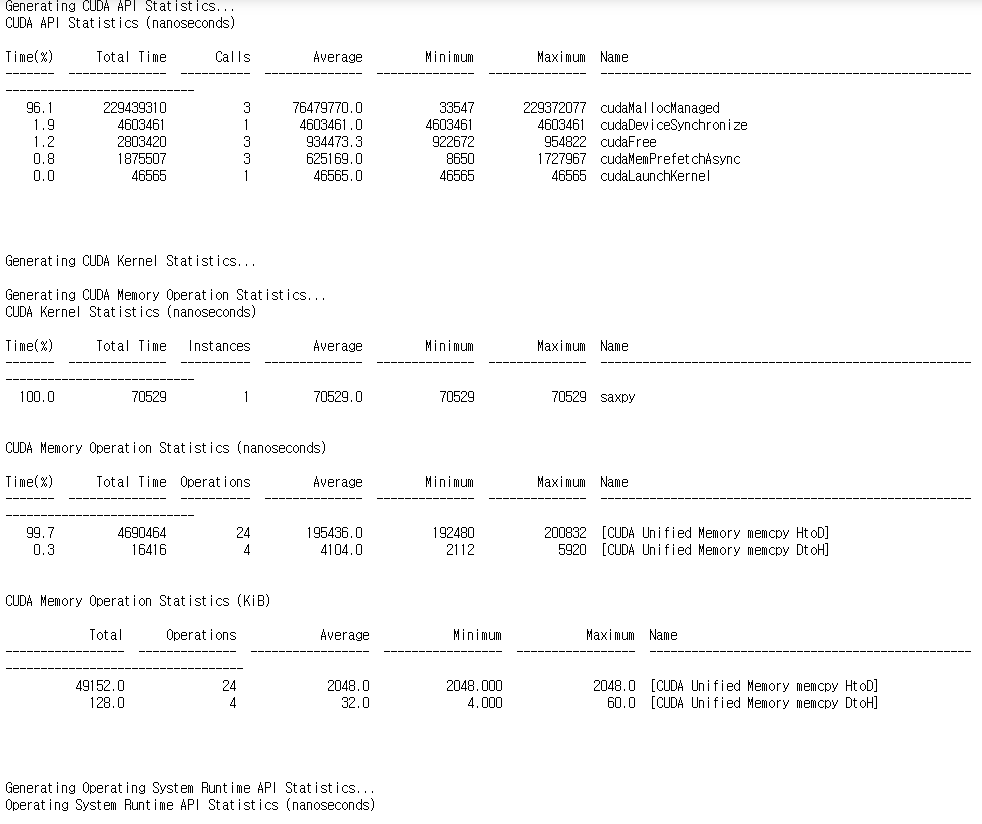
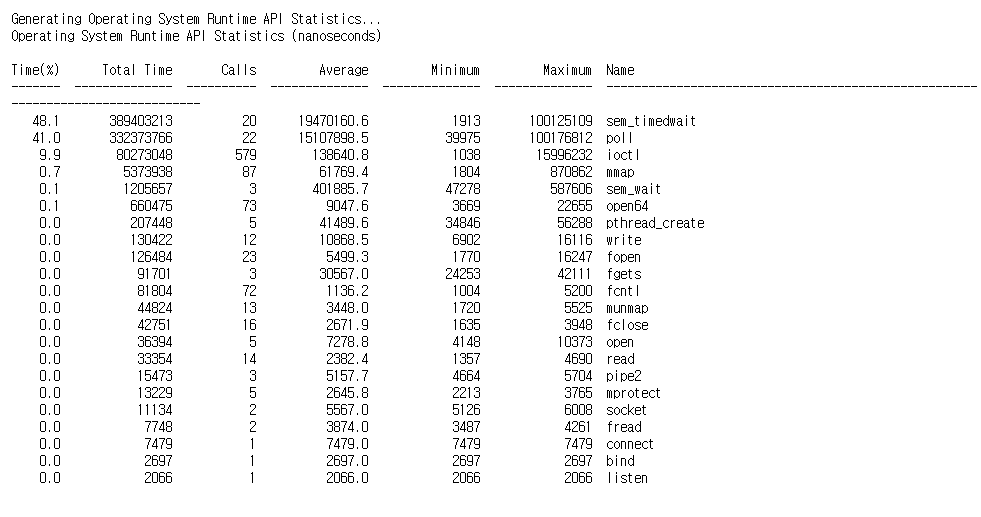
Asynchronous Memory Prefetching
호스트나 디바이스가 메모리에 접근하려고 하면 Page fault가 발생하여 필요한 데이터를 일괄적으로 이동합니다.
이런 Page fault와 요구로 인한 메모리의 이동의 오버헤드를 줄이기 위한 기술을 비동기 메모리 프리패치라고 합니다.
코드를 사용하기 전에 통합메모리를 비동기적으로 이동시켜 GPU 커널과 CPU 성능을 높일 수 있습니다.
Managing Accelerated Application Memory with CUDA Unified Memory and nsys Summary
- At this point in the lab, you are able to:
- Nsight Systems 명령 줄 도구 (nsys)를 사용하여 가속화 된 응용 프로그램 성능을 profile할 수 있었습니다..
- "Streaming MultiProcessors"에 대한 이해를 활용하여 실행 구성을 최적화 해보았습니다.
- Page Faulting 및 Data Migrations과 관련하여 "Unified Memory"의 동작을 이해했습니다.
- 성능 향상을 도모한 Page Faulting및 Data Migrations을 줄이기 위해 "Asynchronous Memory Prefetching"을 사용해보았습니다.
- Iterative Development Cycle를 사용하여 애플리케이션을 빠르게 가속화하고 배포해보았습니다.
- 학습을 통합하고 애플리케이션을 반복적으로 가속화, 최적화 및 배포 할 수있는 능력을 강화하기위해 실습의 최종 실습을 진행했습니다.
- 완료 한 후 시간과 관심이있는 사람들을 위해 만들어진 "고급 컨텐츠"섹션을 진행했습니다.
Iterative Optimizations with the NVIDIA Command Line Profiler
Nsys는 Nsight Systems 명령어 도구다. 응용 프로그램의 GPU 활동 요약, CUDA API 호출 및 Unified Memory 활동에 대한 정보를 출력해줍니다.
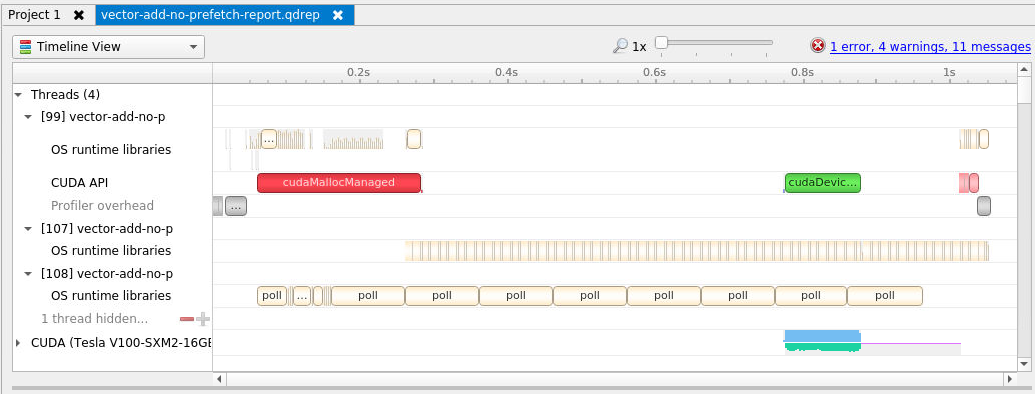
Concurrent CUDA Streams
CUDA 프로그래밍에서 스트림은 순서대로 실행되는 명령이 연속적으로 있습니다.
하지만 기본 스트림 외에 다른 스트림을 생성하여 활용한다면 다중 작업을 서로 다른 스트림에서 동시에 수행할 수 있습니다.
기본 스트림이 아닌 다른 스트림에서 커널을 실행하기 위해서는 커널의 4번째 인수를 사용해야 합니다.
Manual Device Memory Allocation and Copying
cudaMallocManaged()와 cudaMemPrefetchAsync()도 충분히 성능이 좋지만 좀 더 좋게하는 방법이 있습니다.
cudaMalloc()은 메모리를 GPU에 직접 할당하지만 반환되는 포인터는 호스트 코드로 접근이 불가능합니다.
cudaMallocHost()는 CPU에 직접 할당하고 마찬가지로 디바이스 코드는 접근이 불가능합니다.
cudaMemcpy()를 통해 호스트와 디바이스간에 메모리를 복사해서 사용할 수 있습니다.
마무리로 고정된 메모리는 cudaFreeHost()와 cudaFree()로 해제하면 됩니다.
Asynchronous Streaming, and Visual Profiling for Accelerated Applications with CUDA C/C++ Summary
- At this point in the lab, you are able to:
- "Nsight Systems"를 사용하여 GPU 가속 CUDA 애플리케이션의 타임 라인을 시각적으로 Profile했습니다.
- Nsight Systems를 사용하여 GPU 가속 CUDA 애플리케이션에서 최적화 기회를 식별하고 활용해 보았습니다.
- 가속화 된 애플리케이션에서 동시 커널 실행을 위해 CUDA 스트림을 활용 해보았습니다.
- 마지막 연습에서 신체-시뮬레이터를 가속화하기 위해 배운 모든 것을 적용 할 수 있었습니다.
Experience
Experience-이제영
솔직히 nvcc 도큐멘트 보다 잘 만든것 같다.
NVCC를 너무 쉽게 잘 설명해주었다.
Nsight을 왜 설치 하는지 드디어 알게 되었다.
C/C++의 이해가 조금 부족해도 잘 할 수 있었다.
NVCC를 처음 접하는 사람에게 추천합니다.
NVIDIA CUDA를 이해하고 싶은 사람에게 추천합니다.
분산 컴퓨팅에 대해 이해하고 싶은 사람에게 추천합니다.
Experience-박경훈
GPU와 CPU를 다룰 수 있어 흥미로웠다.
Nsight System을 통해 시각적으로 볼 수 있어 재미있다.
단계 별로 비교하는 문제에서 좀 더 구체적인 솔루션이 있었으면 좋겠다
GPU에 관심이 있는 사람에게 추천해주고 싶다.
인증서


긴 글 읽어주셔서 감사합니다! 이번주는 내용이 많으면서도 적어서 최대한 흐름만 적기위해 노력하다보니 더 길어졌습니다!
마찬가지로 모든 리뷰는 주관적이라는점 알아주시면 감사하겠습니다!
앞으로 저희의 리뷰를 통해 Nvidia에서 열리는 DLI 프로그램에 대해 궁금하신점을 해결해가셨으면 좋겠습니다!
지금 리뷰는 내용 요약이 들어가있지만, 실제로 DLI프로그램을 진행하면 직접 코딩하시면서 하실 수 있습니다.
이런 흐름이다~ 라고 생각하시고 보시면 좋을 것 같습니다 ㅎㅎ 감사합니다!
다음주에는 Image Super Resolution Using Autoencoders리뷰로 돌아오겠습니다!
Jeyoung Lee
Assistant Professor at school of computing at Soongsil University. My research interests include EEG, Generate images, Computer Vision, GPU-based data science,Machine learning, and Deep learning.

Comments