안녕하세요, NVIDIA DEEP LEARNING INSTITUTE REVIEW를 진행하고 있는 이제영입니다.
다섯번째 시간입니다! 이번엔 Fundamentals Of Accelerated Data Science With RAPIDS Review로 돌아왔습니다!
안타까운 소식이지만 아마 저희 스터디는 이번주로 마무리 지을 것 같습니다!, 기존에 친구들과 약속한 시간이 다 되었기 때문입니다.
아참 그리고 이번주는 인증서와 관련한 헤프닝이 있었습니다.
여러분들도 Accesment test시에 조심해주세요, 심사 숙고하신 후 제출해주시길 바라겠습니다!
RAPIDS는 Pandas, Numpy등과 유사한 점이 많았습니다!
특히 Scikit-learn에 비해 편한 부분도 없잖아 있었습니다.
그래서 그런지 이번주는 그림이 조금 많네요!
블로그에 주기적으로 올리는 일은 앞으로 적어지겠지만 RAPIDS는 제가 개인적으로 마음에 들었기 때문에 종종 좋은 글이 보이면 해석해서 들고 오겠습니다!
여러분도 한번 RAPIDS를 시작해보는 것이 어떠신가요?
아무튼 이번주 리뷰 시작하도록하겠습니다!
Review

Index
-Summary
-Experience
Summary
Introduction RAPIDS
- Course Goals
- 일상적인 데이터 과학에 RAPIDS를 사용하는 핵심 도구에 대해 배우기
- 워크 스테이션 및 클러스터에서 클라우드 및 HPC까지 RAPIDS의 확장성 이해하기
- 계속해서 RAPIDS 기능을 배울 수 있는 기초 구축
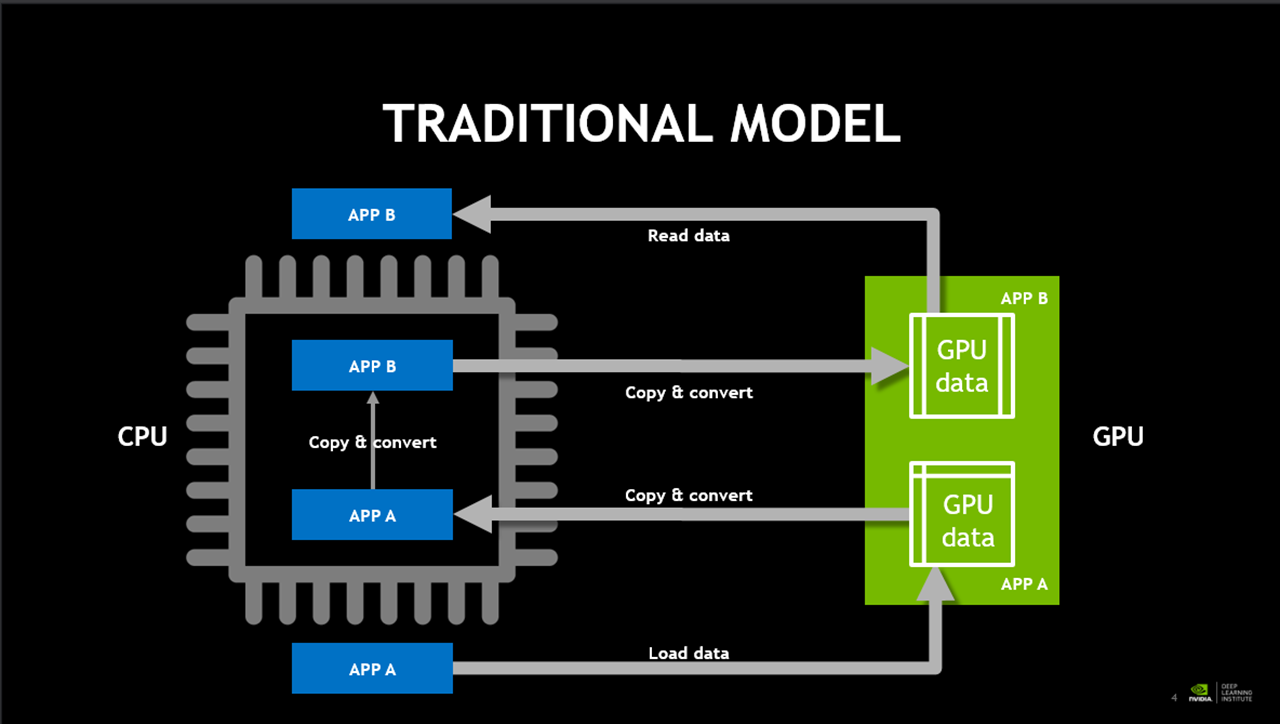 < 전통적인 모델의 GPU 작동 순서도 >
< 전통적인 모델의 GPU 작동 순서도 >
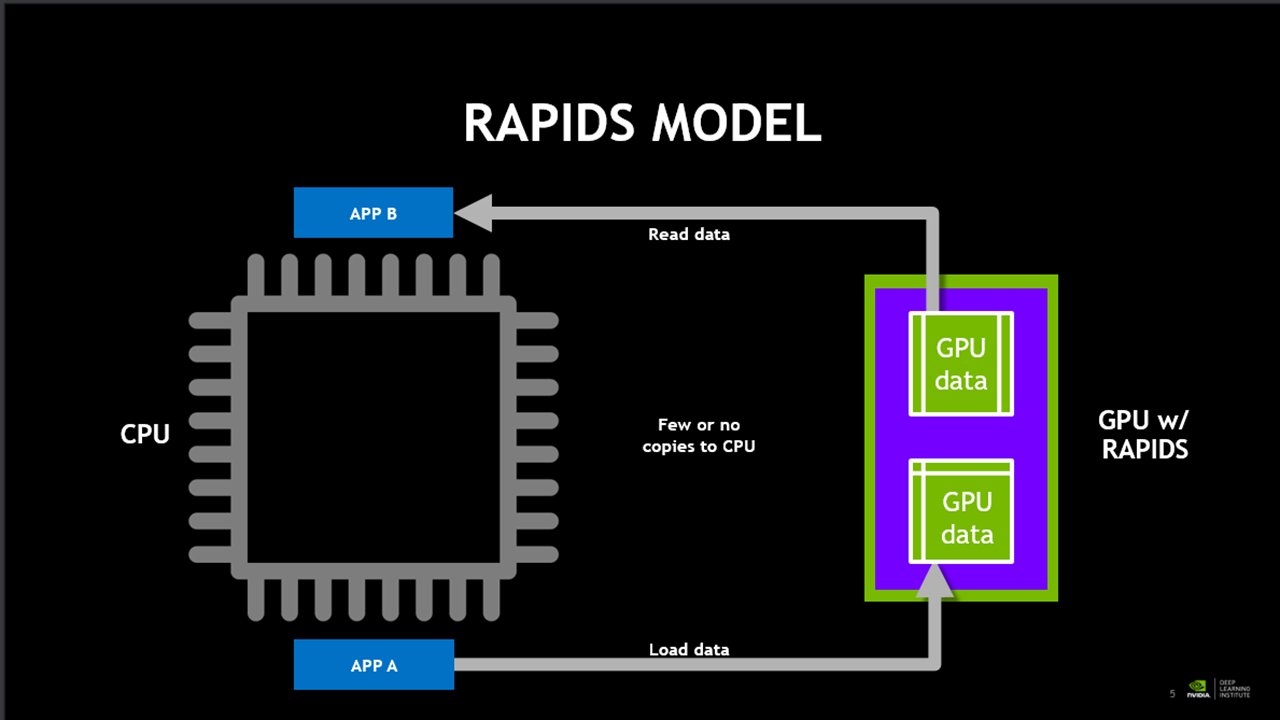 < RAPIDS를 사용한 GPU 작동 순서도 >
< RAPIDS를 사용한 GPU 작동 순서도 >
RAPIDS는 전통적인 모델과는 다르게, CPU와 GPU의 사이의 복사 변환 과정이 별도로 필요하지 않습니다.
따라서 전통적인 모델에 비해서 더 빠른 성능을 낼 수 있습니다.
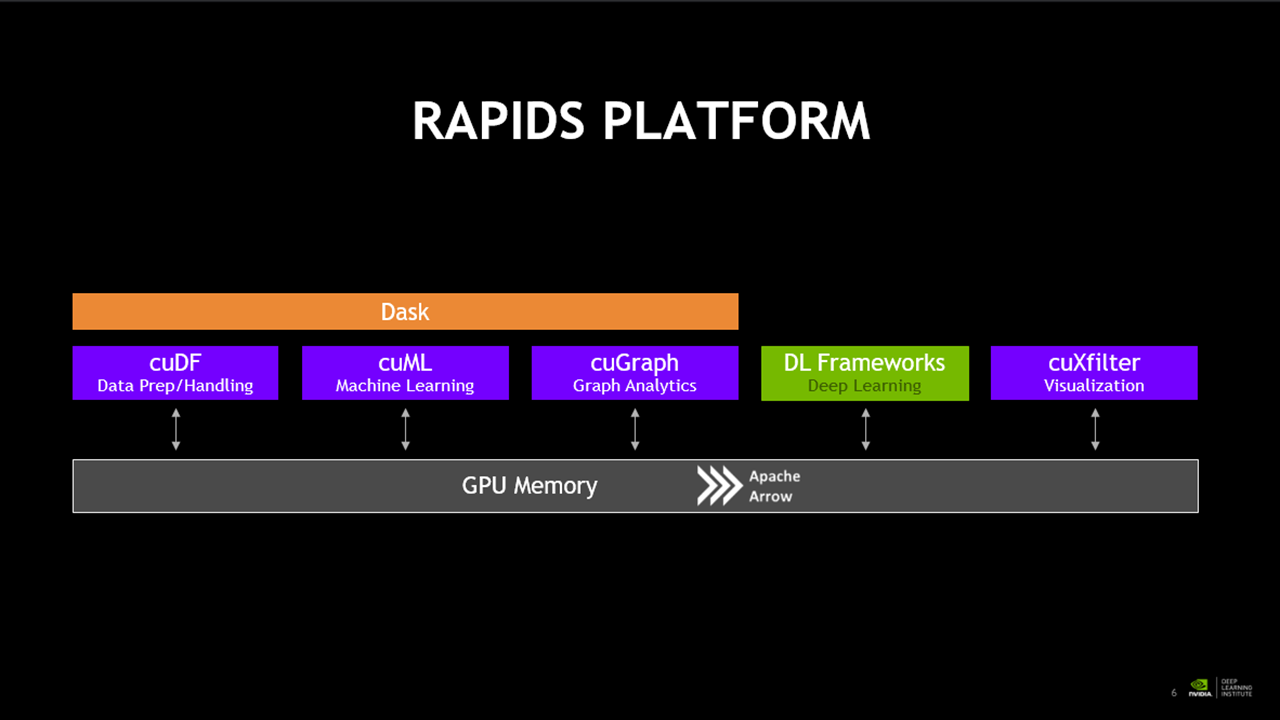 < RAPIDS의 구성 >
< RAPIDS의 구성 >
RAPIDS는 다음과 같이 구성되어 있습니다.
이번 과정에서 우리는 CuDF와, CuML, CuGRAPH, CUXFILTER를 살펴보았습니다.
대부분의 경우 기존의 다른 툴들과 거의 흡사하다는 느낌을 받았습니다.
 < RAPIDS가 지원하는 데이터 과학용 툴 >
< RAPIDS가 지원하는 데이터 과학용 툴 >
RAPIDS에서 사용할 수 있는 데이터 툴들이 어떤 툴과 유사한 기능을 하는지 한눈에 살펴볼 수 있습니다.
이번 스터디에서의 경험상 대부분의경우 CPU를 사용하는 기존의 툴들보다 RAPIDS가 훨씬더 빠른 성능을 내었습니다.
 < RAPIDS의 공식 홈페이지 >
< RAPIDS의 공식 홈페이지 >
저희가 이 과정에서 배우는 것은 극히 일부일 뿐이며, 더 자세한 내용의 위의 공식 홈페이지에서 확인할 수 있었습니다.
[공식 홈페이지 바로가기](https://rapids.ai/)
처음 보시는 분이라면 다소 불편할 수도 있습니다. 하지만 천천히 보시면 금방 익숙해 지실 수 있습니다.
 < CUDF의 설명 >
< CUDF의 설명 >
CuDF란, RAPIDS에서 Data Handling을 담당하는 모듈로서, GPU 가속화된 dataframes를 만들고 조작하도록 돕습니다.
또한 Pandas와 유사한 기능을 가지고 있습니다.
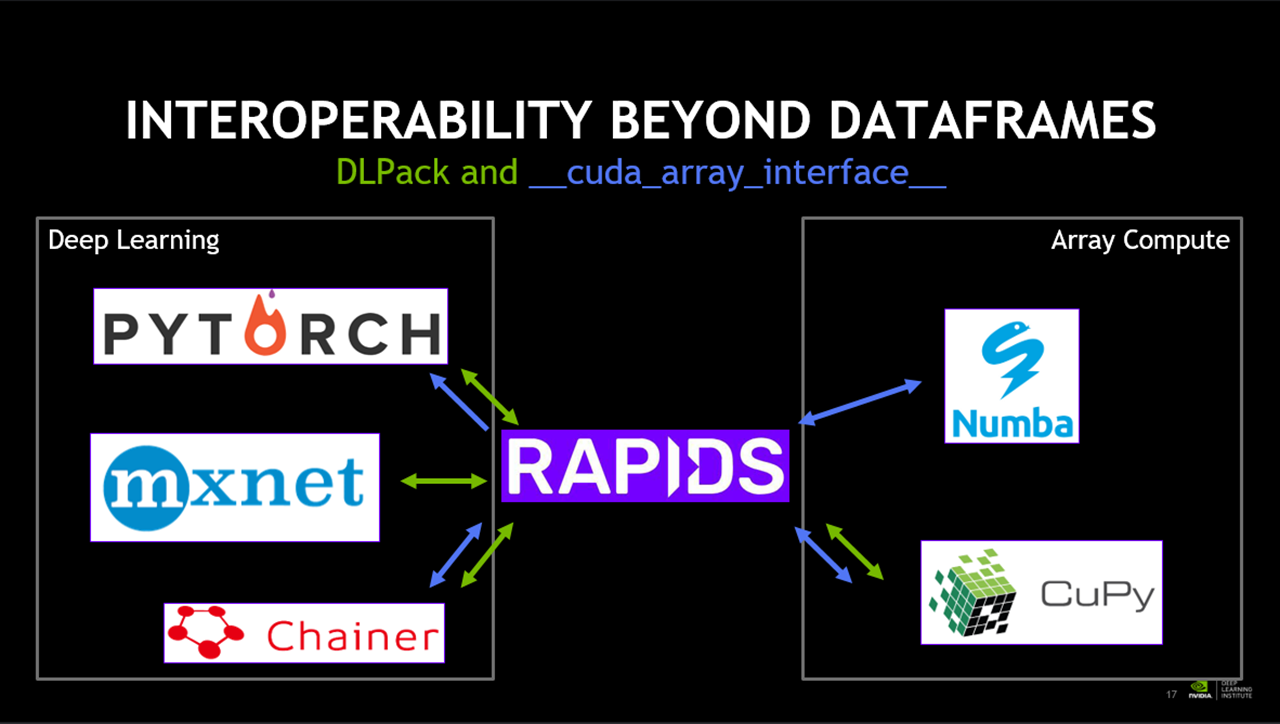 < RAPIDS로 연결할 수 있는 라이브러리들 >
< RAPIDS로 연결할 수 있는 라이브러리들 >
RAPIDS로 핸들링한 데이터들 혹은 RAPIDS를 사용하여 다른 패키지들과 상호 보완적으로 사용할 수 있습니다.
RAPIDS에서 공식적으로 지원하는 팩들과 인터페이스를 가지고 있는것들이 표시되어 있습니다.
 < CuPY의 설명 >
< CuPY의 설명 >
CuPy역시 Data Handling 툴입니다만, 주로 계산의 영역을 담당합니다.
CPU에서 Numpy와 같은 역할을 담당합니다.
사용 방법 역시 유사합니다.
 < CUGRAPH의 설명 >
< CUGRAPH의 설명 >
CuGRAPH는 Graph를 연구하기위한 NetworkX와 거의 유사합니다.
NetworkX를 제가 사용해보지 않아서 용법이 유사한 것 까지는 모르겠습니다.
하지만 CUGRAPH를 활용하여 그래프를 분석하고, xFilter등을 활용하여 Visualize를 진행합니다.
그리고 다음의 용어를 배웠습니다.
unique() – 값
Str.lstrip(‘#’) – 제거
Factorize() – 라벨링
Dask – 병렬 컴퓨팅
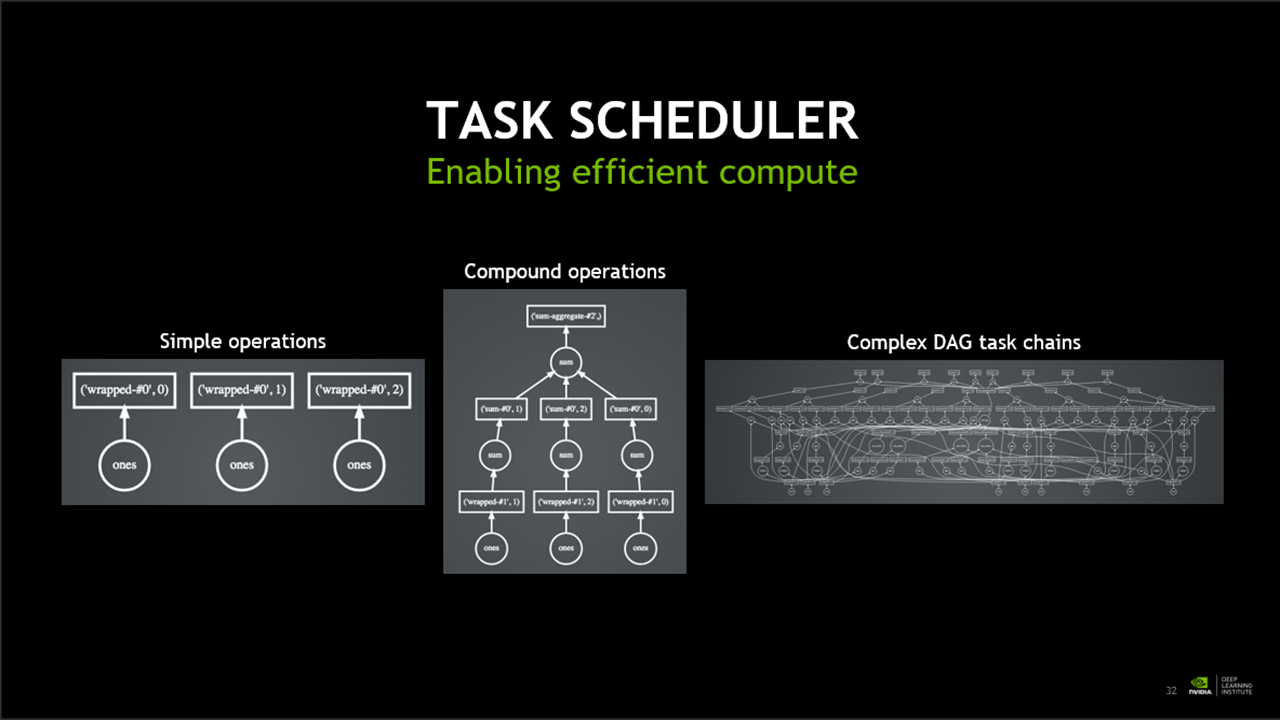 < RAPIDS에서 지원하는 TASK SCHEDULER 모형 >
< RAPIDS에서 지원하는 TASK SCHEDULER 모형 >
또한 다양한 Operation의 SCHEDULER를 제공합니다.
 < CuML의 설명 >
< CuML의 설명 >
마지막으로 CuML입니다.
저는 개인적으로 Scikit-learn과 유사하다는 느낌을 많이 받았습니다.
이번 과정에서는 위에 보이는 5개의 알고리즘을 CuML를 사용하여 다루어 보았습니다.
솔직히 다루는 방법보다는 데이터가 어떻게 생겼는지를 더 많이 살펴본 것 같습니다.
Experience
Experience-이제영
RAPIDS는 굉장히 좋은 것 같다.
솔직히 Numpy, Numba, Pandas, Scikit-learn등을 따로 배우는 것 보다 편하고 좋은 것 같다.
과정 자체도 만족스럽다.
누구에게나 추천한다.
데이터 사이언스를 배우고 싶으면 비추천한다.
RAPIDS의 Document가 생각보다 불편하게 되어 있는데, 이 과정을 수강하면 매우 도움이 될 것이다.
아직 RAPIDS가 완성이 아닌 것 같아 앞으로의 버전이 매우 기대가 된다.
Experience-박경훈
CPU와 GPU의 속도차이를 결과로 확인할 수 있어서 좋았다.
Pandas와 상당히 유사하기 때문에 접근하기 쉬웠다.
개인적으로 강의가 루즈해서 별로였다.
Experience-구정수
GPU를 사용하여 데이터 분석을 빠르게 수행할 수 있었다.
CPU만을 사용하는 경우와 비교해서 속도 차이가 컸다.
Pandas, Numpy와 많은 부분에서 유사해서 기존의 데이터 과학을 배운 사람들이 손쉽게 사용할 수 있을 것이라 생각한다.
Jupyter Lab 환경이 매우 편리했다.
인증서



긴 글 읽어주셔서 감사합니다! 이번 과정은 배우는 내용보단 RAPIDS를 배운다는 느낌이 강합니다!
저는 매우 만족했던 과정이었던 것 같습니다. 특히 다들, Accesment에서 굉장히 헤매더라고요...
혹시 이 과정에 대해 관심 있으시면, 저희의 리뷰를 참고하시면 좋을 것 같습니다.
거듭 말씀드리지만 리뷰는 저희들의 개인적인 의견이며, 실제 과정에서는 위의 내용들과 더불어 코딩하시면서 배우실 수 있습니다!
한달동안 고생 많이 하셨습니다! 저희 DLI Review 스터디는 이로써 막을 내리지만, DLI 과정은 꾸준하게 열리고, 업데이트 되고 있습니다.
시작하기 앞서서, 어떤 과정인지 간단히 살펴보고 어떤느낌인가 정도를 보실때 참고가 되셨으면 좋겠습니다!
또한 궁금한점이 있으시면 언제든지 메일 바라겠습니다. 기다리고 있겠습니다.
마지막으로 홍보 하나만 하겠습니다!
NVIDIA 는 AI 스타트업의 비즈니스/기술 개발에 필요한 여러 자원들을 지원해주는 인큐베이팅 프로그램을 운영하고 있고 전세계적으로 약 5,800 개의 스타트업들과 협력 노력을 하고 있습니다!
이 프로그램의 일환으로 실제 AI 기술을 적용하는 AI 스타트업에게 실질적인 지원을 해주고자 중소벤처기업부와 함께 N&UP 프로그램을 진행한다고 합니다!
NVIDIA 엔지니어 분들이 심사위원으로 참여하며 무려 사업 지원비 최대 3억, 뽑힌 30개의 기업들끼리 추가 심사를 통해 R&D 투자비 최대 4억을 지원해주는 프로그램이라고 합니다!
자세한 내용은 링크 남기도록 하겠습니다!
[온라인 세미나](https://youtu.be/L717kWEmgbY)
[모바일에서 자세히 보기](http://me2.do/FTnFsv66)
[PC에서 자세히 보기](http://me2.do/FoAMy5jr)
감사합니다! 다음번에 다른 포스트로 다시 찾아뵙겠습니다!
Jeyoung Lee
Assistant Professor at school of computing at Soongsil University. My research interests include EEG, Generate images, Computer Vision, GPU-based data science,Machine learning, and Deep learning.

Comments