Abstract
Signal Dice Similarity Coefficient
A Structure-Aware Metric for Semantic Signal Representation Learning
Jeyoung Lee,
Hochul Kang
Department of Digital Media Engineering
The Catholic University of Korea
Abstract
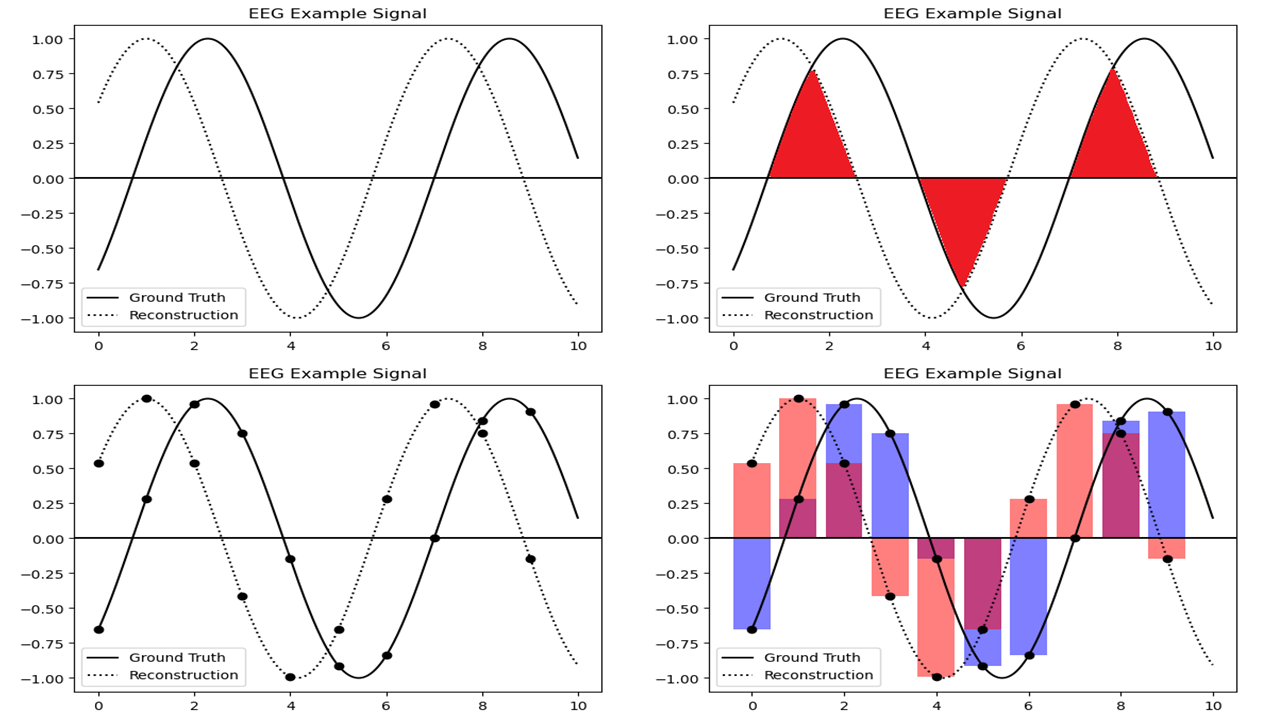
MSE vs SDSC Example
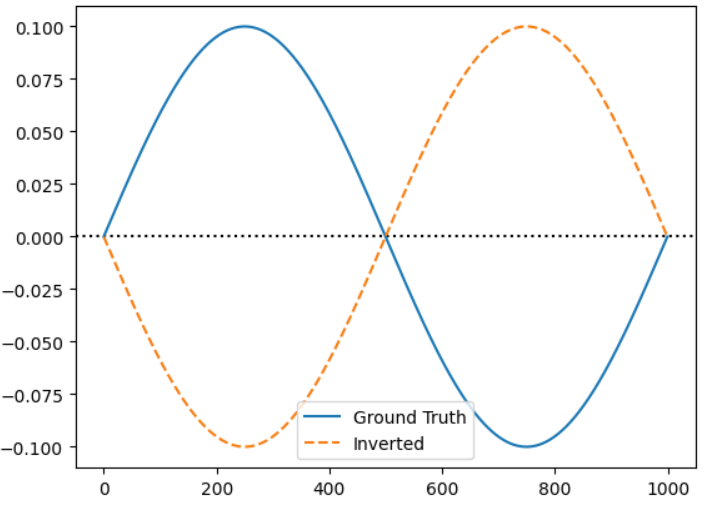
Inverted : MSE=0.0200, SDSC=0.0000
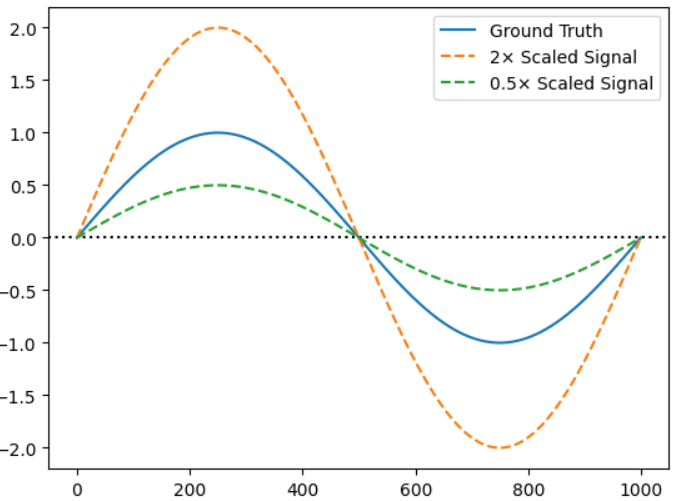
Scaled 0.5x : MSE=0.1249, SDSC=0.6667
Scaled 2x : MSE=0.4995, SDSC=0.6667
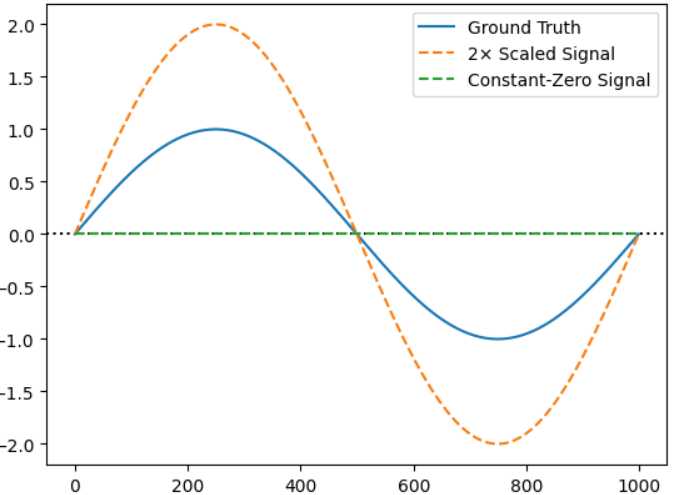
Zero : MSE=0.4995, SDSC=0.0000
Scaled 2x : MSE=0.4995, SDSC=0.6667
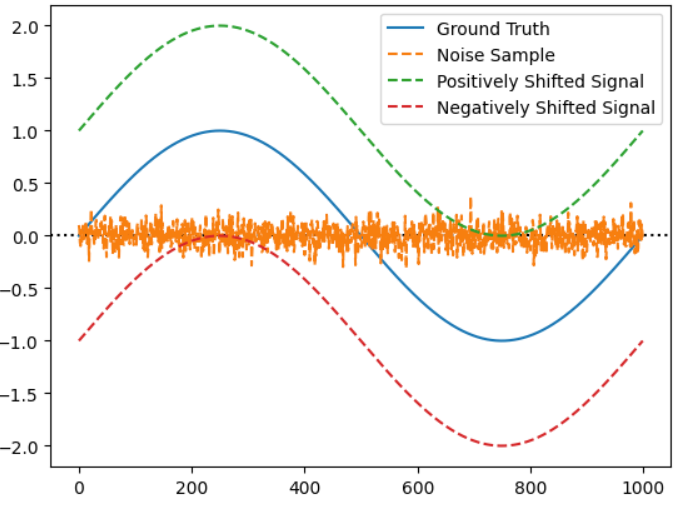
Shifted ± 1: MSE=1.0000, SDSC=0.3887
Noise : MSE=0.5062, SDSC=0.1137
Although numerically favorable, the output is structurally misaligned and functionally misleading. Such insensitivity to signal semantics is particularly problematic for physiological data like EEG or ECG, where subtle structural components often carry diagnostic significance. Therefore, exclusive reliance on amplitude-centric metrics may lead to semantically incorrect reconstructions.
Definition of SDSC
The SDSC extends DSC's concept to the signal domain by interpreting the area under the curve as a proxy for the waveform structure.
The objective in signal representation learning is to maximize SDSC toward 1. However, directly computing SDSC via integration is infeasible in practice, as realworld signals, such as EEG, lack known analytical expressions. To address this, a discrete approximation is adopted.
Since the SDSC score is bounded in [0, 1], we can define the loss as 1 − SDSC(·).
However, the use of the Heaviside step function in the SDSC introduces discontinuities, which can negatively affect the stability of training. To enable stable gradient-based optimization, a smooth approximation of the Heaviside function is introduced. The following sigmoid-based formulation is used, with a sharpness parameter α.