안녕하세요, 두번째 챕터 Cupy Part 01입니다.
오늘은 Cupy의 기초부터 시작하도록 하겠습니다.
그리고 코드위주로 작성할 예정이기 때문에 원본코드를 먼저 첨부하겠습니다.
원본코드 보러가기
Cupy?
Cupy란 무엇일까요?
대부분의 사람들의 경우 python에서 수학적인 계산을 할 때 Numpy를 많이 사용할 것이라고 생각합니다.
Numpy는 훌륭하고, 빠르고, 편하고, 좋은 라이브러리입니다.
하지만 CPU에서 돌아간다는 점 때문에 대규모 작업을 처리할 때 작업시간이 조금 부담스러울 때가 있습니다.
Cupy란, Python에서 NVIDIA CUDA를 사용한 가속화 컴퓨팅을 제공하는 오픈소스 라이브러리입니다.
Cupy는 Numpy를 뛰어 넘는 속도를 보여주다고합니다.
심지어, 자체 테스트에선 연산이 100배 이상 차이나는 경우도 있었다고 합니다.
RAPIDS에서 제공하는 자체 Bechmark 기사를 같이 첨부하겠습니다.
Single-GPU Cupy Speedups
그렇다면 이런 Cupy는 어떻게 사용하는 걸까요?
주피터 노트북 환경에서, 쉘별로 확인해보도록 하겠습니다.
Import 하기
import cupy as cp
import numpy as np
이번 과정에서는 항상 Numpy와 Cupy 모두를 Import 할 예정입니다.
실제 환경에서는 Numpy를 Cupy로 바꾸는 것 만으로 대부분의 코드가 포팅 가능하게 됩니다.
왜냐하면 Numpy와 Cupy는 Method가 동일하기 때문입니다.
하지만 실제론 조금 다른 부분도 있습니다. 중요한 부분은 이번 챕터에서 보고 넘어가도록 하겠습니다.
Simple Test Code
간단한 코드를 통해 사용법을 보도록하겠습니다.
먼저 Numpy 버전 코드입니다.
%%time
x_num = np.arange(6).reshape(2,3).astype("f")
print("X : ", x_num)
print("X sum : ", x_num.sum(axis=1))
!nvidia-smi

다음은 Cupy 버전 코드입니다.
%%time
x_cp = cp.arange(6).reshape(2,3).astype('f')
print("X : " , x_cp)
print("X sum : ", x_cp.sum(axis=1))
!nvidia-smi
 지난번에 보았던 설치 부분에서도 봤던 코드와 유사합니다.
지난번에 보았던 설치 부분에서도 봤던 코드와 유사합니다.
결과 출력된 화면을 보면, GPU메모리가 올라간게 보이시나요?
GPU에 Array가 올라갔음을 알 수 있습니다.
Time
그런데 한가지 이상한 점이 있습니다.
Numpy보다 빠르다고 이야기를 했는데, 위의 코드에서는 Numpy가 Cupy보다 동작 시간이 더 짧음을 볼 수 있습니다.
어째서 Numpy의 동작 시간이 더 빨랐을까요?
지금의 경우에는 연산량이 작기 때문입니다.
무슨 이야기냐면, GPU는 항상 CPU보다 빠른것이 아닙니다.
다음과 같은 상황에서는 CPU가 GPU보다 빠른 성능을 낼 수도 있습니다.
- 계산량이 충분하지 않은 경우
- 잘못된 구조로 GPU 아키텍쳐를 만들었을 경우
- (쉘 동작 시간에서는)처음 호출하는 경우
지금의 경우 3번과 1번에 해당하는 상황인 것 같습니다.
자 그러면 실제로 연산량이 많을수록 Cupy가 동작시간이 더 짧은지 코드로 확인해보겠습니다.
Computing Time Test
지금 부터 간단하게 연산 시간 테스트를 해보겠습니다.
랜덤하게 생성한 N * N 크기의 행렬을 두개 만든 후, 내적을 실행해보겠습니다.
그리고 N의 크기를 증가 시켜가면서 속도를 테스트 해 볼 예정입니다.
직접 해보셔도 좋고, 결과만 보고 가셔도 괜찮습니다.
Case 1. n=100
numpy
%%time
a = np.random.rand(n,n)
b = np.random.rand(n,n)
result = np.matmul(a,b)
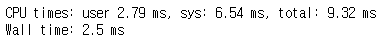
cupy
%%time
a = cp.random.rand(n,n)
b = cp.random.rand(n,n)
result = cp.matmul(a,b)
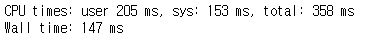
Case 2. n=1000
numpy
%%time
a = np.random.rand(n,n)
b = np.random.rand(n,n)
result = np.matmul(a,b)
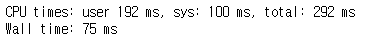
cupy
%%time
a = cp.random.rand(n,n)
b = cp.random.rand(n,n)
result = cp.matmul(a,b)
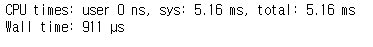
Case 3. n=10000
numpy
%%time
a = np.random.rand(n,n)
b = np.random.rand(n,n)
result = np.matmul(a,b)
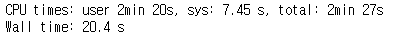
cupy
%%time
a = cp.random.rand(n,n)
b = cp.random.rand(n,n)
result = cp.matmul(a,b)
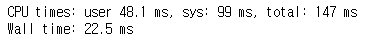
확실히 연산량이 늘어나면 늘어날수록 Numpy에 비해 Cupy가 훨씬 빠른 속도를 냄을 알 수 있습니다.
반면 n이 작을땐, Numpy가 속도가 더 빠른걸 볼 수 있습니다.
Cupy Data Type
처음 Cupy 매서드와 Numpy의 매서드가 거의 동일하다고 말씀 드렸습니다.
그렇다면 데이터 타입도 같을까요?
한번 확인해보겠습니다.
Num_array = np.arange(6)
print(Num_array)
print(type(Num_array))
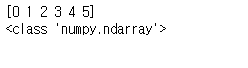
Cupy_array = cp.arange(6)
print(Cupy_array)
print(type(Cupy_array))
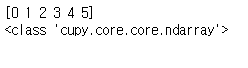 둘이 데이터 타입이 조금 다름을 알 수 있습니다.
둘이 데이터 타입이 조금 다름을 알 수 있습니다.
ndarray이긴 하나, Numpy의 ndarray와 cuda의 core에 올라가있는 cupy의 ndarray입니다.
.get()
그렇다면, cupy ndarray를 numpy ndarray타입으로 바꿀 수는 없을까요?
밑에 추가로 바꾸는 방법이 나오지만, 우선 .get()은 자주 사용할 예정임으로 따로 만들었습니다.
cupy array뒤에 .get()을 붙임으로 numpy ndarray로 만들 수 있습니다.
cpu_array = Cupy_array.get()
print(cpu_array)
print(type(cpu_array))
Cupy Method
마지막으로 앞으로 자주 쓰일 매서드를 몇가지만 살펴보도록 하겠습니다.
Numpy 사용이 익숙하신 분들은 이 부분은 넘어가셔도 관계 없습니다.
또한 제대로 이해하시려면 documentation을 참고하시기 바랍니다.
지금은 쉽게 사용하기 위해 꼭 필요한 부분만 적어 넣었습니다.
cupy documentation
실습 코드와 결과는 원본 코드를 참고해주시길 바라겠습니다.
cupy.array(arg)
cupy ndarray를 반환합니다.
cupy.arange(strat, stop=None, step=1, dtype=None)
시작부터 끝지점까지 step 간격을 가진 cupy ndarray를 반환합니다.
cupy.empty(shape, dtype)
초기화한 cupy ndarray를 반환합니다.
cupy.ones(shape, dtype)
1로 초기화한 cupy ndarray를 반환합니다.
cupy.zeros(shape, dtype)
0으로 초기화한 cupy ndarray를 반환합니다.
cupy.linalg.norm(cupy.ndarray)
Euclidean norm(a.k.a L2 norm)한 결과를 반환합니다.
cupy.cuda.Device(int).use()
cupy는 기본적으로 gpu 0을 사용하게 되어있습니다.
이 명령어를 통해 원하는 gpu로 옮길 수 있습니다.
cupy.asnumpy(cupy.ndarray)
앞서 잠깐 살펴보았던 .get()메서드와 같은 역할입니다.
둘 중 원하는 방법으로 사용하셔도 무방합니다.
cupy.add(array1, array2)
두 어레이의 원소별 덧셈을 반환합니다.
cupy.subtract(array1, array2)
두 어레이의 원소별 뺄셈을 반환합니다.
cupy.multiply(array1, array2)
두 어레이의 원소별 곱셈을 반환합니다.
cupy.divide(array1, array2)
두 어레이의 원소별 나눗셈을 반환합니다.
cupy.power(array1, array2)
두 어레이의 원소별 승곱을 반환합니다.
cupy.mod(array1, array2)
두 어레이의 원소별 나머지를 반환합니다.
cupy.absolute(array)
어레이의 원소별 절대값을 취한 값을 반환합니다.
cupy.exp(array)
어레이의 원소별 Exponential 결과를 반환합니다.
cupy.log(array)
어레이의 원소별 log를 수행합니다.
cupy.sqrt(array)
어레이의 원소별 sqaure root 연산을 수행합니다.
cupy.square(array)
어레이의 원소별 제곱연산을 수행합니다.
cupy.sin, cupy.cos, cupy.tan
다양한 삼각함수들도 지원하고 있습니다.
cupy.equal(array1, array2)
두 어레이의 각 원소별로 값이 같은지 비교하여 반환합니다.
cupy.maximum(array1, array2)
두 어레이의 각 원소별로 큰 값을 반환합니다.
cupy.minimum(array1, array2)
두 어레이의 각 원소별로 작은 값을 반환합니다.
cupy.floor(array)
원소별 floor연산을 수행 후 반환합니다.
cupy.ceil(array)
원소별 ceil연산을 수행 후 반환합니다.
마치며
이것으로 오늘 과정을 마무리 하겠습니다.
오늘은 기초 부분이라 명령어의 연속이었습니다.
실은 cupy document를 참고 하셔도 무관합니다.
다음에는 cupy를 이용한 선형대수 표현에 대해서 이야기해보겠습니다.
질문 및 이야기는 언제든지 부탁드리겠습니다.
질문은 제가 활동하고 있는 사이트 Devstu에서 부탁드리겠습니다.
질문 하러 가기
Jeyoung Lee
Assistant Professor at school of computing at Soongsil University. My research interests include EEG, Generate images, Computer Vision, GPU-based data science,Machine learning, and Deep learning.

Comments